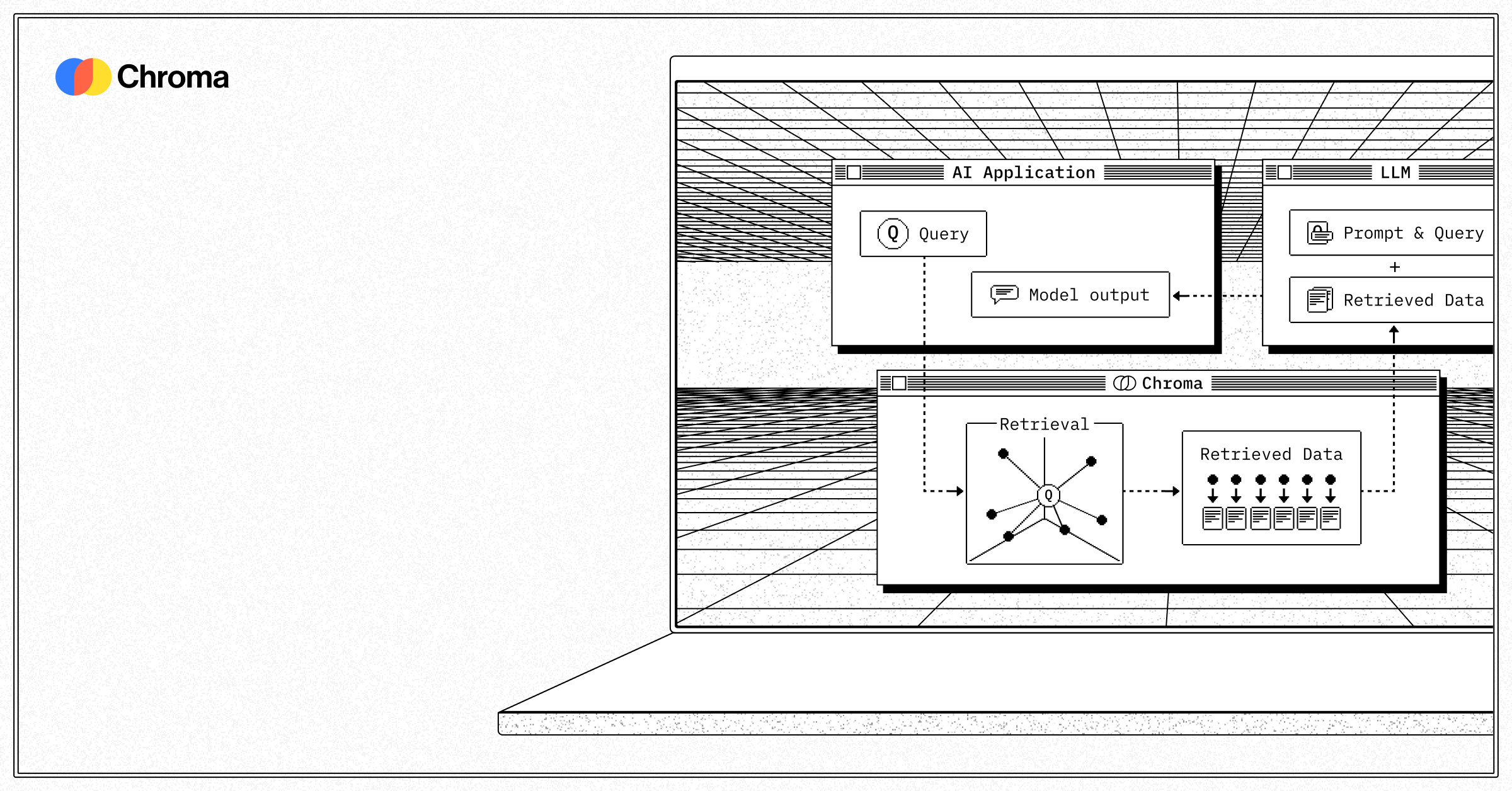
01 MCP Server
Pinecone MCP Server
The #1 managed vector database - sub-10ms queries at billion-vector scale.
pinecone.ioPinecone is the industry standard for production vector search. This MCP Server connects your agent to serverless vector indexes with sub-10ms query latency, hybrid sparse-dense retrieval, and built-in metadata filtering. From semantic search to real-time RAG grounding - your agent gets instant access to billions of embeddings without managing a single shard.
Serverless vector indexing & search
Hybrid sparse-dense retrieval
Metadata filtering & namespaces