LiteLLM (LLM Proxy & Spend Tracking) MCP Server
Manage your LLM gateway via LiteLLM — generate API keys, track spending, and orchestrate model fallback paths.
Vinkius AI Gateway soporta streamable HTTP y SSE.

Funciona con todos los agentes de IA que ya usas
…y cualquier cliente compatible con MCP
LiteLLM MCP Server: mira tu AI Agent en acción
Capacidades integradas (10)
create_model
Inject completely fresh routing endpoints (ex: new Bedrock Llama 4 endpoints)
create_team
Generate pristine organizational isolation tracking exact cost limits per division
create_user
Insert specific End-User identities bridging Vinkius with Proxy logs
delete_key
Delete an existing LLM proxy key entirely
delete_model
Delete explicitly routed LLM deployments preventing 500s dynamically
generate_key
Generate a new proxy API key isolating distinct microservices or teams
get_key_info
Get configuration and budget bounds for a specific LiteLLM API Key
get_model_info
Get array endpoints tracing exact Fallback paths like OpenAI -> Anthropic
get_team_info
Get internal logic bounds matching multiple routing users via Team UUID
get_user_info
Return precise End-User abstractions tracking total USD consumed natively
Lo que este conector desbloquea
Connect your LiteLLM Proxy instance to any AI agent and take full control of your LLM infrastructure, load balancing, and spend management through natural conversation.
What you can do
- Key Orchestration — Generate and manage proxy API keys to isolate distinct microservices or teams, including precise budget and rate limit constraints directly from your agent
- Model Routing Intelligence — Get detailed info on fallback paths (e.g., OpenAI -> Anthropic -> Groq) and verify exact routing endpoints assigned to your models
- Real-time Spend Audit — Track total USD consumed by specific end-users or teams and monitor budget ceilings to ensure cost-effective AI deployments
- Dynamic Model Control — Inject fresh routing endpoints (e.g., new AWS Bedrock or Azure OpenAI deployments) into your proxy runtime with zero downtime
- Team & Organizational Isolation — Create and manage team profiles to track exact cost limits and operational boundaries per organizational division
- Infrastructure Security — Instantly vaporize malicious or leaked keys and remove broken LLM deployments to prevent downstream 500 errors dynamically
How it works
1. Subscribe to this server
2. Enter your LiteLLM API URL and Master Key
3. Start managing your LLM gateway from Claude, Cursor, or any MCP-compatible client
Who is this for?
- Platform Engineers — manage global LLM gateway configurations and audit model fallback paths through natural conversation
- AI Ops Teams — monitor real-time AI spending and adjust team budgets across multiple LLM providers
- Backend Developers — generate sub-keys for new microservices and verify model routing availability without leaving your IDE
Preguntas frecuentes
Dale a tus agentes de IA el poder de LiteLLM
Accede a LiteLLM y a más de 2.000 servidores MCP — listos para que tus agentes los usen, ahora mismo. Sin código pegamento. Sin integraciones personalizadas. Solo conecta el Vinkius AI Gateway y deja que tus agentes trabajen.
Más en esta categoría
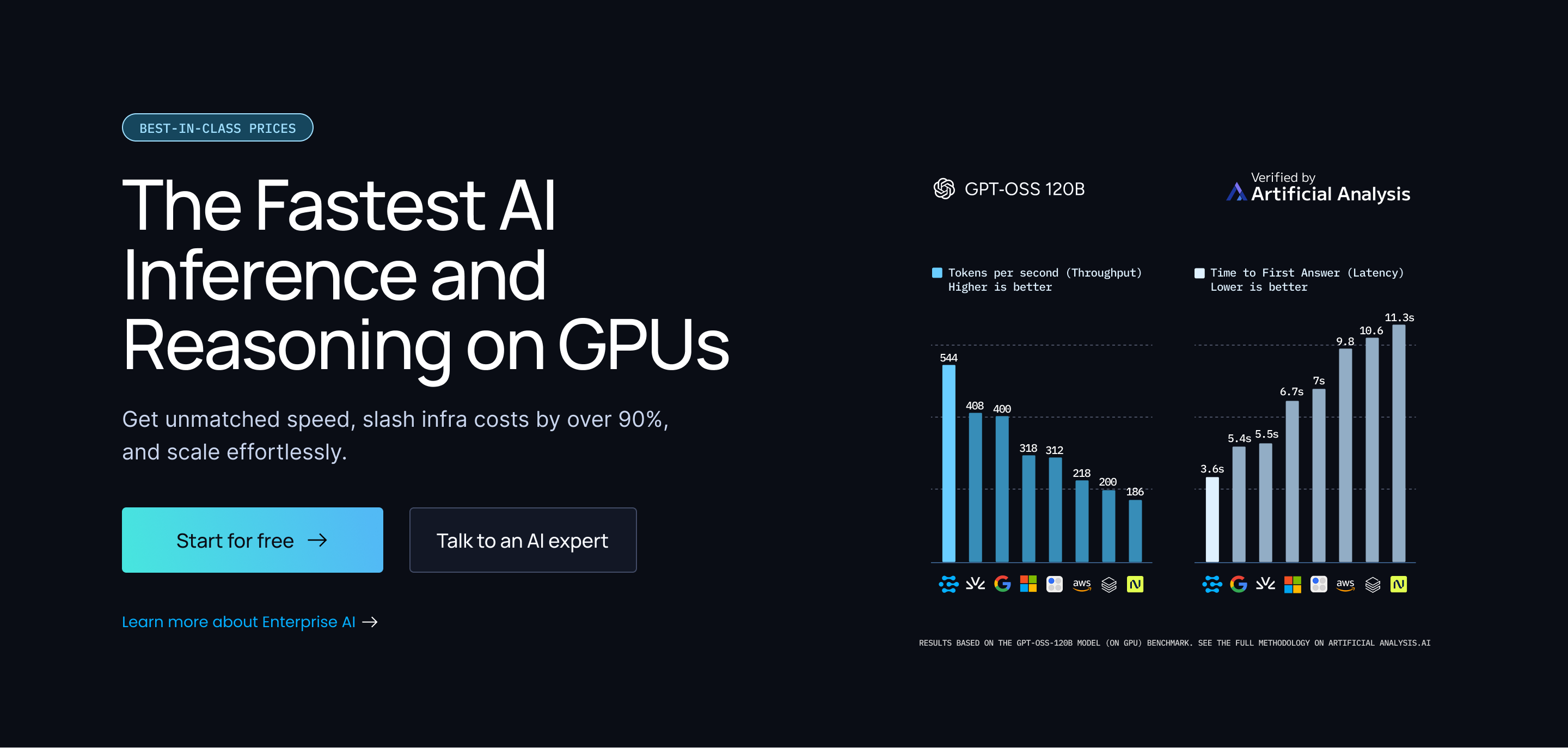
Clarifai (Vision AI)
6 herramientasManage AI inference via Clarifai — list apps, models, and workflows, and perform computer vision predictions directly from any AI agent.

New Relic AI (LLM Observability)
10 herramientasMonitor and audit LLM telemetry via New Relic AI — track token costs, p95 latency, and user feedback.

Anyscale
7 herramientasOrchestrate your Anyscale infrastructure — manage LLM queries, vectors, services, and cluster batch jobs directly from your AI agent.
También podría gustarte

Orderful
8 herramientasEDI integration made simple — manage transactions, relationships, and guidelines via Orderful.
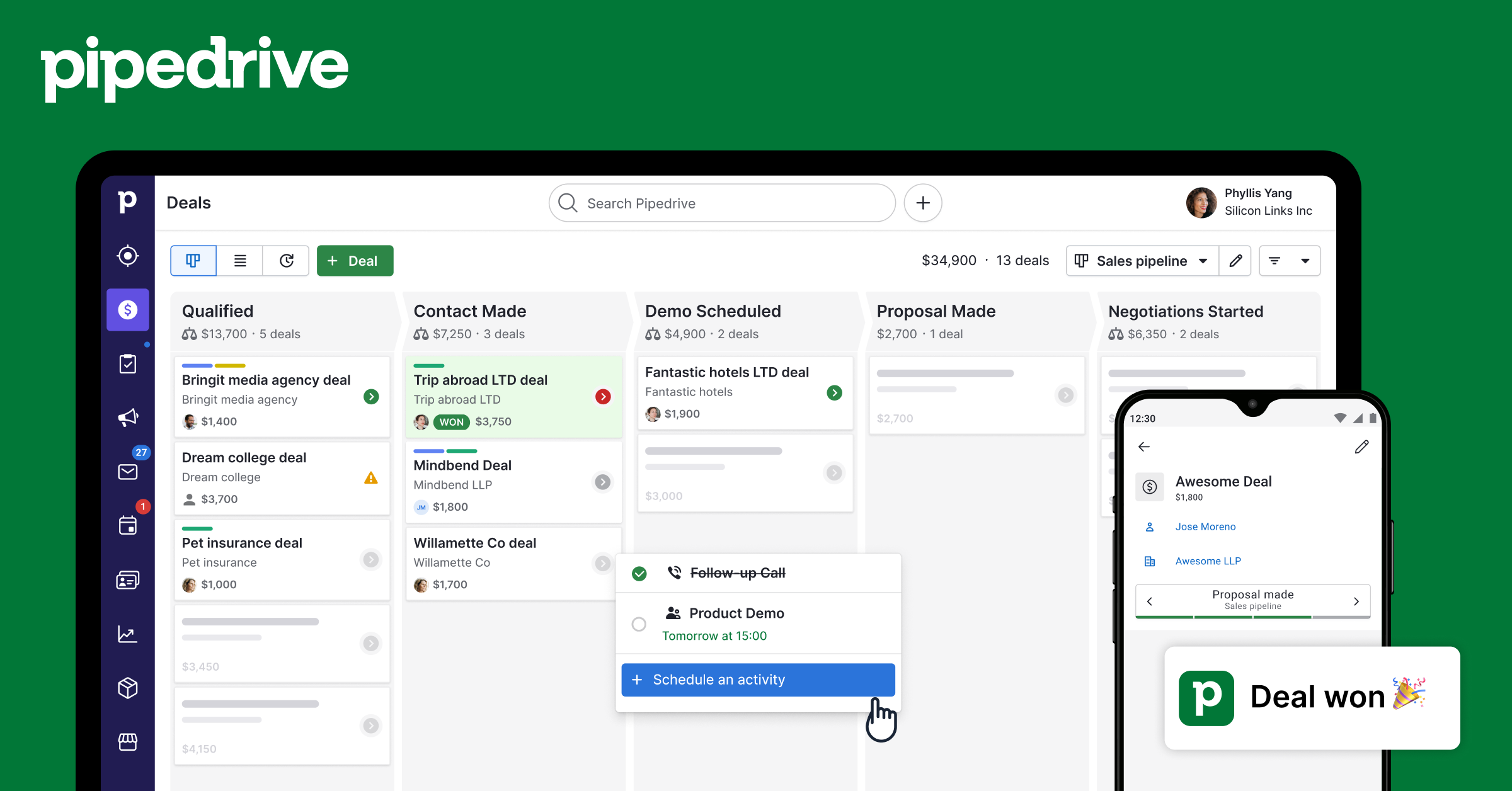
Pipedrive Activities
8 herramientasCreate and manage calls, meetings, tasks, emails, and deadlines — full activity tracking for your Pipedrive account.
ezyVet
12 herramientasManage your veterinary practice via ezyVet — list patients, appointments, invoices, and consults directly through your AI agent.