Chroma Vector DB MCP. Audit, Search, and Manage Your Embedded Knowledge Base
 Gemini
Gemini Works with every AI agent you already use
…and any MCP-compatible client
Just plug in your AI agents and start using Vinkius.
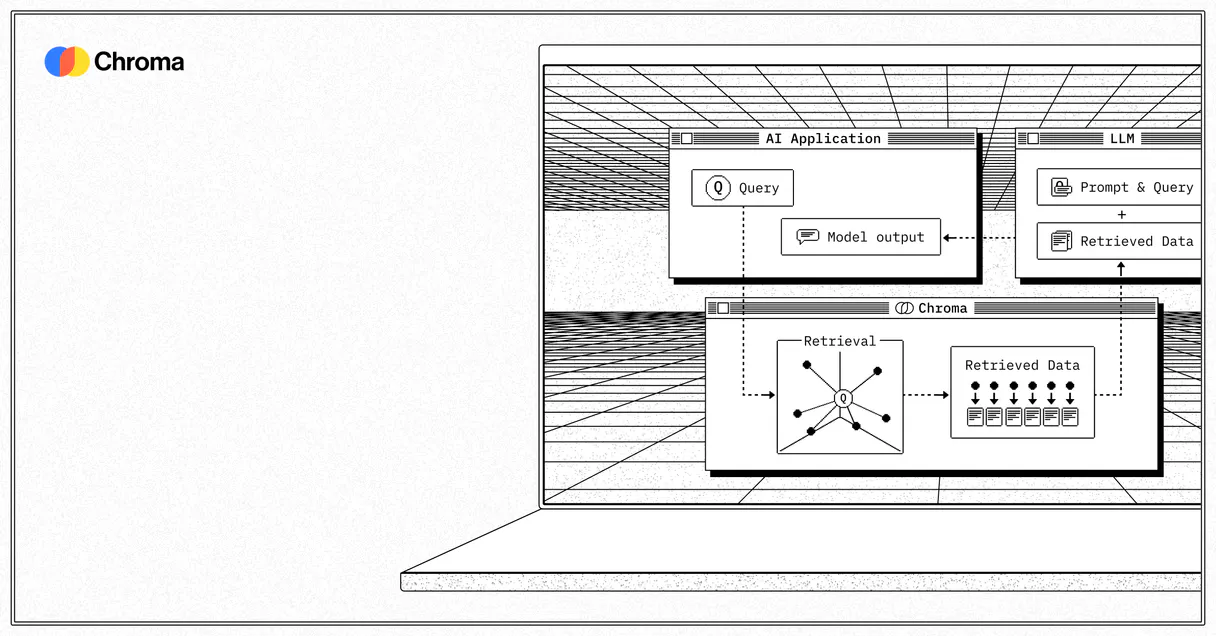
Chroma (Vector DB) MCP gives your AI agent full control over semantic data. List collections, perform high-dimensional vector similarity searches, and audit document counts in natural conversation.
It lets you manage private knowledge bases directly from your chat client.
What your AI agents can do
Check heartbeat
Tests network availability against explicit Chroma API nodes to confirm connectivity status.
Count documents
Calculates and reports the total number of documents stored in a specified collection.
Get collection
Retrieves detailed configuration and metadata for one specific vector knowledge block.
Validates network availability and connectivity against the Chroma API nodes.
Retrieves a list of every defined vector collection within your database tenant.
Provides an exact total count of document volumes across specified collections.
Pulls specific, raw documents and their associated semantic context from known arrays.
Extracts a quick look at the metadata or content of your database limits without needing to pull everything.
Identifies precise logical bounds that match high-dimensional semantic clustering criteria.
Ask AI about this MCP
Supported MCP Clients
OAuth 2.0 Compatible Gemini Waiting for input…
Chroma (Vector DB) with 7 Tools
Use these tools to interact directly with your vector database. Check system health, count records, or run advanced semantic queries using plain chat commands.
Make your AI actually useful.
Add this MCP to Claude, Cursor, or Windsurf and your AI stops guessing. It gets real tools to look things up, take action, and handle the stuff you keep doing by hand.
Start using Chroma (Vector DB) on Vinkius019d756fcheck heartbeat
Tests network availability against explicit Chroma API nodes to confirm connectivity status.
019d756fcount documents
Calculates and reports the total number of documents stored in a specified collection.
019d756fget collection
Retrieves detailed configuration and metadata for one specific vector knowledge block.
019d756fget documents
Pulls the actual text content and semantic context from known document arrays.
019d756flist collections
Generates a list of all defined vector collections available in your database tenant.
019d756fpeek documents
Shows a limited preview of the metadata attached to your database limits for quick inspection.
019d756fquery embeddings
Performs high-dimensional vector similarity searches based on semantic input queries.
Choose How to Get Started
Build a custom MCP for your own tools, or connect a ready-made integration from our catalog.
Build Your Own
Turn any API into an MCP. Import a spec, define Agent Skills, or deploy with MCPFusion.
- Import from OpenAPI, Swagger, or YAML specs
- Create Agent Skills with progressive disclosure
- Deploy to edge with MCPFusion framework
- Built in DLP, auth, and compliance on every call
- Real time usage dashboard and cost metering
- Publish to catalog or keep private
Make Your AI Do More
Start with Chroma (Vector DB), then connect any of our 4,900+ other servers whenever your AI needs more. One click, no limits.
- Use this MCP plus 4,900+ others, all in one place
- Add new capabilities to your AI anytime you want
- Every connection is secured and compliant automatically
- Track usage and costs across all your servers
- Works with Claude, ChatGPT, Cursor, and more
- New servers added to the catalog every week
Independent Platform Disclaimer: Vinkius is an independent platform and is not affiliated with, endorsed by, sponsored by, verified by, or otherwise authorized by Chroma. All third-party trademarks, logos, and brand names are the property of their respective owners. Their use on this website is strictly for informational purposes to identify service compatibility and interoperability.
VINKIUS INFRASTRUCTURE
Cloud Hosted
Managed infra
V8 Isolated
Sandboxed per request
Zero-Trust Proxy
No stored credentials
DLP Enforced
Policy on every call
GDPR Compliant
EU data residency
Token Compression
~60% cost reduction
Works with Claude, ChatGPT, Cursor, and more
The Model Context Protocol standardizes how applications expose capabilities to LLMs. Instead of operating in isolation, your AI gains direct access to external platforms, live data, and real-world actions through secure, standardized connections.
This server provides 7 capabilities that interface natively with Claude, ChatGPT, Cursor, and any MCP client. No middleware. No custom integration required.
Tracking Data Volume Across Multiple Environments
Today, checking how many documents are in your staging versus production environments means jumping between dashboards, running multiple CLI commands, and manually cross-referencing volume numbers. You end up with a spreadsheet filled with siloed metrics that take hours to reconcile.
With this MCP, you simply ask the agent, 'What is the document count for both prod and staging?' It runs the necessary checks and gives you a consolidated report instantly. The context flows directly into your chat window.
Get Document Visibility with `get_documents`
Manually fetching documents used to require writing specific queries that only returned document IDs, forcing you to run a second query just to see the actual text content. You'd then have to copy-paste the results into another system for review.
Now, running `get_documents` gives you both the full semantic context and the raw data in one go. You get immediate visibility without leaving your chat.
What you can do with this MCP connector
When your AI needs to answer questions using proprietary or complex documents, it can't just guess; it needs context. This MCP connects your agent straight into Chroma, giving it visibility over your entire vector data layer. You stop writing boilerplate Python code for debugging and start asking simple questions—like 'How many records are in the staging environment?' or 'Find me all docs related to API authentication.' It's about talking to your knowledge base instead of querying a database schema.
By using this MCP through Vinkius, you give your agent the power to look at exactly what context it needs from your vector store, handling everything from listing available collections to retrieving specific document IDs.
019d756f-4ffd-70e6-a58d-1ab35cbe3608 How Chroma Vector DB MCP Works
- 1 First, subscribe to this MCP and provide your Chroma URL (Cloud or self-hosted) and the required API Key.
- 2 Next, tell your AI agent what you want to check—for instance, 'Show me all available collections' or 'Count documents in X.'
- 3 Your agent executes the necessary tool call and returns the structured data directly into the chat window.
The bottom line is you get full visibility into your vector embeddings using only natural conversation.
Who Is Chroma Vector DB MCP For?
This MCP is for ML Engineers, Data Scientists, and DevOps Ops who spend too much time writing scripts just to check if their knowledge base is healthy or how many documents are actually in the system. It lets you audit vector data without leaving your chat interface.
Uses it to debug retrieval logic by running query_embeddings and verifying that the returned context matches the expected semantic cluster.
Checks instance health using check_heartbeat or audits overall stability by calling count_documents across different environments.
Inspects collection metadata with get_collection and uses list_collections to map out the entire scope of data available for their agent.
What Changes When You Connect
- Debugging retrieval logic is fast. Instead of writing a script to test search boundaries, you just run
query_embeddingsthrough your agent's chat interface. - You always know what data exists. Use
list_collectionsto see every single knowledge silo andget_collectionfor its specific settings—no guesswork required. - Maintain operational confidence by checking system stability with
check_heartbeat. You get immediate confirmation that the connection is live before running a complex query. - Understand your data footprint. Run
count_documentsto track volumes across different tenants, ensuring you're not running expensive searches on empty collections. - Inspect raw context easily. Need to see what documents are attached without pulling all the data? Use
peek_documentsfor a quick metadata preview.
Real-World Use Cases
Verifying staging environment readiness
A PM needs to know if their new documentation set is ready. They ask, 'What collections exist for the Q3 rollout?' The agent runs list_collections, and they immediately see if the expected staging database was populated.
Debugging a failed search query
A developer suspects the wrong data is being returned. They use peek_documents to check the metadata of documents in the 'user-embeddings' collection, confirming that the source and date fields are correctly attached before running query_embeddings.
Auditing data growth over time
A data engineer needs to prove compliance by tracking records. They run count_documents across all production tenants, getting a precise total volume that they can report directly from the chat.
Checking connectivity before deployment
Before running any complex queries, an ops team member runs check_heartbeat. A successful response confirms the instance is fully operational and ready for high-volume traffic.
The Tradeoffs
Assuming collections exist
A user tries to run a search query immediately, but doesn't know if the required data set was uploaded or what its name is.
→
Always start by running list_collections first. This shows you all defined vector collections so you can target your search accurately with query_embeddings.
Confusing counts with live data
Getting a document count from one tool and assuming that every document is fully indexed for semantic searching.
→
If you need to verify the content or structure, use get_collection to check its configuration. For actual content retrieval, use get_documents.
Overlooking system status
Running a complex query that times out because the underlying database node is temporarily disconnected.
→
Before anything else, run check_heartbeat. This verifies fundamental network availability and prevents wasting time on failed queries.
When It Fits, When It Doesn't
Use this MCP if your core problem involves making sense of unstructured data or verifying the state of a proprietary knowledge base. It's perfect when you need to ask questions about what context is available (using list_collections and get_collection) or how much data exists (count_documents). Don't use it if your task is simple CRUD—like just updating one user record in a standard SQL table. For those tasks, you need a different type of API connector. Use this when the bottleneck is semantic understanding and visibility into vector embeddings.
Common Questions About Chroma Vector DB MCP
How do I see which vector collections are available using `list_collections`? +
Running list_collections returns a clear list of every defined knowledge silo in the database. This helps you identify exactly where your data lives before running any other query.
What is the difference between `count_documents` and `peek_documents`? +
count_documents gives you a single number: the total volume of records. peek_documents shows you a small, readable sample of the metadata or content attached to those documents.
Do I need to run `check_heartbeat` before querying embeddings? +
It's smart practice to check connectivity first. Running check_heartbeat confirms that your network connection is live and the Chroma instance is fully operational, preventing failed searches.
What if I want to know more about a specific collection using `get_collection`? +
You simply ask for details on the name of the collection. The agent uses get_collection and returns its full configuration, helping you understand its scope and metadata.
If I run `query_embeddings` with a vector that is too large or malformed, how does the system handle it? +
The system validates input dimensions first. If the vector doesn't match the expected embedding size for a collection, the query fails immediately. This prevents corrupted data from running through your semantic search pipeline.
How do I ensure that my staging environment is isolated when using `get_collection`? +
You must explicitly manage tenant context before calling get_collection. Always confirm your API key and connection URL point to the correct database instance. Never assume the current context handles environment switching for you.
What specific metadata do I receive back when I use the `get_documents` tool? +
You get the full document content, but critically, you also get associated metadata like the source ID, creation timestamp, and any custom fields attached to that record. This lets you trace information back to its origin.
If my `check_heartbeat` call returns an error, what does that mean for running other commands? +
It means the fundamental connection is broken; no operation will succeed until connectivity is restored. You must address the network or credential issue before attempting to run any data retrieval tools.
Multi-server workflows that include Chroma (Vector DB) MCP
MCP Servers for AI-Powered Trend Detection
By the time a trend reaches your Twitter feed it is too late to act , Tavily detects signals from primary sources, Chroma builds a semantic map that reveals connections between weak signals, and Notion tracks emerging trends weeks before they go mainstream
MCP Servers to Build AI Training Datasets
You need a dataset of 10,000 product listings for your RAG system but there is no API , Apify scrapes them, Chroma stores them as searchable embeddings, and Notion tracks every data source with quality scores
Use it with your favorite AI tools
Connect this server to Cursor, Claude, VS Code, and more.