Chroma (Vector DB) MCP, Ready to Go
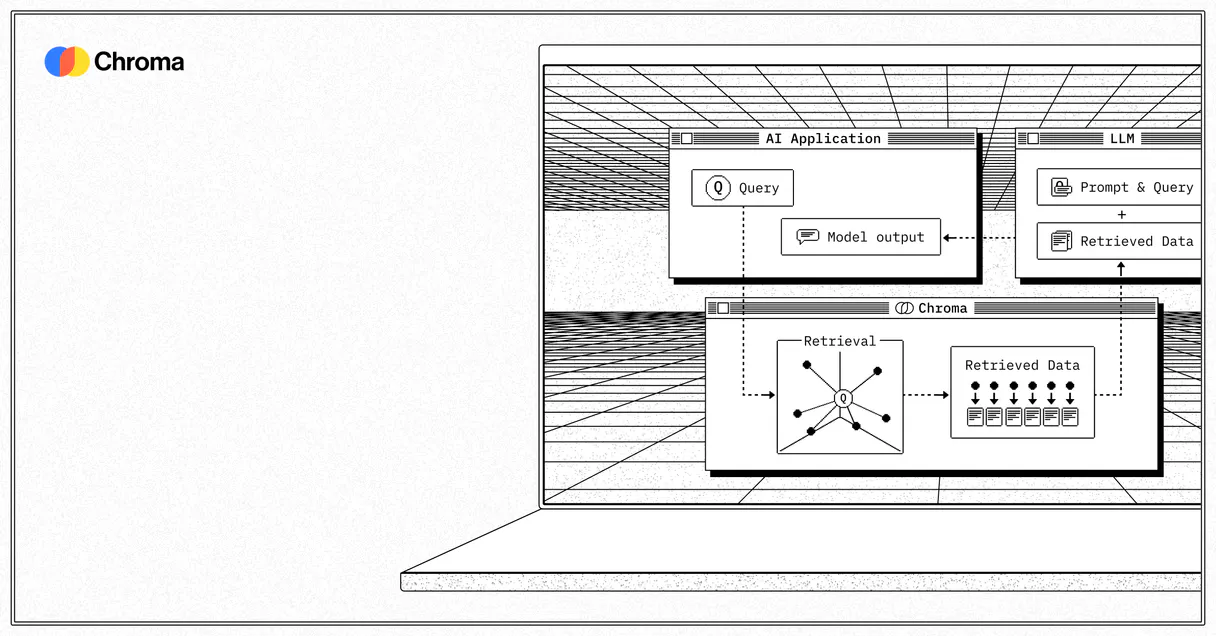
Connect your AI agents to Chroma using this Connector to manage vector embeddings, audit documents, and run semantic searches in your AI client.
No credit card required. Experience the power of this integration risk-free.
Search and manage your vector embeddings using natural language.
Works with every AI agent you already use
…and any MCP-compatible client
How fast is the Chroma (Vector DB) Connector?
Average time for the server to become ready for requests over the last 14 days, measured until the initialize / tools/list handshake completes. Metrics are updated daily between 00:00 and 04:00 UTC. Create a free account, use this Connector on Vinkius Cloud, and connect it to your AI agent in seconds.
Waiting for input…
What AI agents can do with Chroma (Vector DB) 7-Tool Vector Database Manager
Use these tools to query embeddings, audit document counts, and manage your Chroma collections.
List collections
See every vector collection in a specific tenant database. This helps you get a clear picture of your data organization at a glance.
Get collection
View the logical settings and configurations for a specific collection. You can use this to check how your data is being bounded or grouped.
Count documents
Get the total number of documents currently in a collection. It's the fastest way to check if your data ingestion scripts finished correctly.
Get documents
Get the exact physical documents and semantic context from a collection. This lets you see the raw data your agent is actually using for answers.
Query embeddings
Find documents that match specific high-dimensional semantic clusters. Use this to test how well your semantic search handles different types of queries.
Peek documents
Get a bounded preview of the database limits and content. It's great for a quick look at the data without pulling the entire collection.
Check heartbeat
Check if the Chroma API nodes are online and reachable. Use this to make sure your connection is active before starting a heavy task.
A Connector is a URL. Vinkius runs it: hosting, security, governance, observability.
You're looking at one of 5,800+ managed Connectors. The real value isn't the catalog. It's the control plane that secures, governs, audits, and manages every interaction between your agents and the tools they use.
No Shadow AI
Every agent action is visible, approved, and auditable. Nothing runs outside your governance.
Absolute agent control
Fine-grained permissions for every agent, MCP, and tool. Instantly revoke access and audit every execution.
Cost control per token
Spend broken down to the token, tool, and agent. Budgets and hard limits. No surprise invoices.
Managed & monitored infra
We operate the runtime, authentication, scaling, retries, and monitoring. Your team manages AI, not infrastructure.
Data protection, DLP by design
Sensitive data is filtered before reaching the model. Access is governed so agents receive only the information they're allowed to use.
Token optimization, real savings
Lower AI costs by delivering the right context instead of unnecessary tools. Better accuracy, faster responses, and fewer wasted tokens.
Fix Vector Database Management with Chroma (Vector DB) MCP
This is for the AI developer who is tired of writing boilerplate Python scripts to check their data, the data engineer auditing production volumes, and the product manager who needs to see what context the AI is actually using.
AI Developer
Debugging vector search logic and testing RAG pipelines using natural language.
Data Engineer
Auditing collection volumes and metadata consistency across different environments.
Product Manager
Inspecting the context being fed to AI agents by peeking at stored embeddings.
DevOps Engineer
Monitoring instance connectivity and heartbeats for self-hosted Chroma nodes.
Frequently Asked Questions
Can I use Chroma (Vector DB) MCP with my own self-hosted instance? +
Yes. You can connect to any Chroma instance, whether it's hosted in the cloud or on your own local hardware, just by providing your URL and API key.
How do I check if my embeddings are actually in the database? +
You can use the Connector to query specific collections and see the document counts or peek at the content to confirm your data was indexed correctly.
Can I see the metadata for my vector collections? +
Yes. The Connector allows your agent to inspect the logical settings and configurations for any specific collection in your database.
Does Chroma (Vector DB) MCP work with Chroma Cloud? +
It works perfectly with Chroma Cloud. You just need to provide your cloud URL and API key to get started.
How do I switch between different database tenants? +
You can ask your agent to switch between different tenants or databases on the fly to isolate your production and staging environments.
Can I use this to find specific documents by meaning? +
Yes. You can ask your agent to perform a semantic search to find documents that match the specific meaning or context of your query.
How do I check if my database is online? +
You can simply ask your agent to check the heartbeat, and it will confirm if your Chroma API nodes are reachable and operational.
Can my agent perform semantic search across my collections? +
Yes. Provide the vector embedding array in JSON format, and your agent will return the closest document matches along with their distance metrics. It is the perfect way to test your RAG (Retrieval-Augmented Generation) logic without complex scripts.
How can I verify the health of my self-hosted Chroma instance? +
Simply ask your agent to check the heartbeat. The agent performs a nanosecond-level responsiveness test against your API nodes, confirming the physical database is active and reachable from the gateway.
I manage multiple tenants — how do I switch between them? +
You can define the tenant and database names during the setup phase. If you need to switch often, you can update the credentials in the dashboard. The agent uses these values for all collection and document operations to ensure strict isolation.
Your AI, connected to everything.












No credit card required · Free tier available













Other Connectors in this category
Pinecone Connector
Equip your AI agent to manage your Pinecone vector databases. Query embeddings, fetch metrics, manage collections, and run stats natively via chat.
Postman Connector
Design, test, and document APIs collaboratively with the world most popular API development platform used by millions of developers.
HTML to Text Extractor Connector
Stop wasting AI context on messy HTML code. Instantly strip CSS, tags, and scripts to extract perfectly readable Plain Text.
Related Connectors

Squarespace Connector
Equip your AI with read-only superpowers over your Squarespace platform. Scan transactions, track orders, and audit inventory effortlessly.
Greenspark Connector
Embed climate action into your product via Greenspark. Plant trees, offset carbon, and track impact via AI.

No-Consecutive-Shift-Generator Connector
Automated work rotation scheduling that prevents fatigue-inducing Night-to-Day transitions.
Powerful workflows with this Connector
Connectors for AI-Powered Trend Detection
By the time a trend reaches your Twitter feed it is too late to act , Tavily detects signals from primary sources, Chroma builds a semantic map that reveals connections between weak signals, and Notion tracks emerging trends weeks before they go mainstream
Connectors to Build AI Training Datasets
You need a dataset of 10,000 product listings for your RAG system but there is no API , Apify scrapes them, Chroma stores them as searchable embeddings, and Notion tracks every data source with quality scores