Integrate.io MCP. Manage data pipelines and audit ETL jobs via chat.
 Gemini
Gemini Works with every AI agent you already use
…and any MCP-compatible client
Just plug in your AI agents and start using Vinkius.
Integrate.io (ETL & Data Integration) MCP Server manages your entire data pipeline lifecycle. List all pipelines, check job runs, and audit transformations directly from your AI client.
You get full visibility into your data warehouse flow and connection health without jumping between dashboards. It lets you monitor ETL jobs, view schemas, and manage credentials in one conversation.
What your AI agents can do
Get account
Retrieves your Integrate.io account status, including limits and usage metrics.
Get pipeline
Gets detailed information, including schemas and nodes, for a specific data pipeline ID.
List connections
Lists every API and database connection configured in your account.
Retrieves a full list of all configured data packages in your account, giving you an overview of your data sources.
Fetches the detailed schema, nodes, and variables for one selected pipeline by its unique ID.
Retrieves a complete list of every API and database connection used by your data workflows.
Gets a history of all executed jobs, allowing you to see which pipelines ran, when, and if they succeeded or failed.
Retrieves a catalog of all data mapping rules and transformations set up in your account.
Provides real-time metrics on your workspace credits and usage limits.
Ask AI about this MCP
Supported MCP Clients
Gemini Waiting for input…
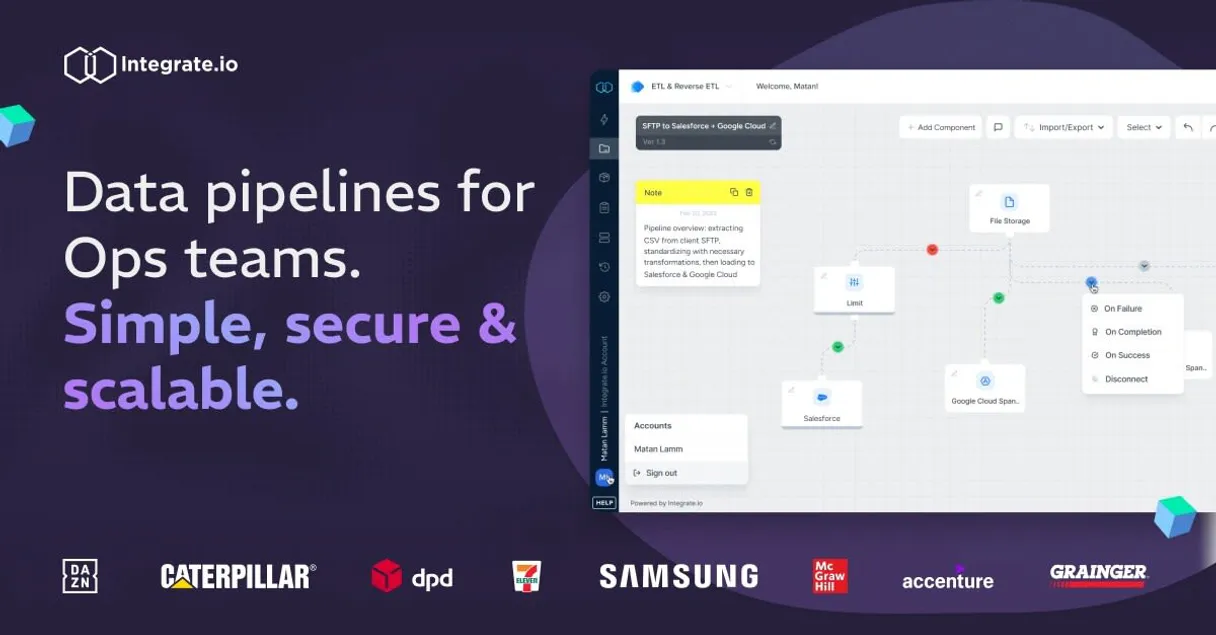
Integrate.io MCP Server: 6 Tools for Data Pipelines
Use these six tools to list, monitor, and inspect every component of your data workflow, from pipelines to connections, through your AI agent.
019d75baget account
Retrieves your Integrate.io account status, including limits and usage metrics.
019d75baget pipeline
Gets detailed information, including schemas and nodes, for a specific data pipeline ID.
019d75balist connections
Lists every API and database connection configured in your account.
019d75balist jobs
Retrieves a history of all pipeline runs, showing success/failure status and timestamps.
019d75balist pipelines
Lists all active and inactive data pipelines configured in your account.
019d75balist transformations
Lists every defined data mapping rule and transformation logic in your account.
Choose How to Get Started
Build a custom MCP for your own tools, or connect a ready-made integration from our catalog.
Build Your Own
Turn any API into an MCP. Import a spec, define Agent Skills, or deploy with MCPFusion.
- Import from OpenAPI, Swagger, or YAML specs
- Create Agent Skills with progressive disclosure
- Deploy to edge with MCPFusion framework
- Built in DLP, auth, and compliance on every call
- Real time usage dashboard and cost metering
- Publish to catalog or keep private
Make Your AI Do More
Start with Integrate.io (ETL & Data Integration), then connect any of our 4,700+ other servers whenever your AI needs more. One click, no limits.
- Use this MCP plus 4,700+ others, all in one place
- Add new capabilities to your AI anytime you want
- Every connection is secured and compliant automatically
- Track usage and costs across all your servers
- Works with Claude, ChatGPT, Cursor, and more
- New servers added to the catalog every week
What you can do with this MCP connector
Yo, if you run data pipelines, you know the drill. You gotta keep tabs on everything—the connections, the jobs, the rules. The Integrate.io MCP Server lets your AI client manage your whole data flow without you having to jump through a dozen dashboards. It’s all right here, in one chat.
You get full visibility into your data warehouse operation, period.
list_pipelines gives you a full list of every data package you've set up, so you can see all your sources at a glance. You can then call get_pipeline using a specific ID to pull up the detailed schema, nodes, and variables for just that one pipeline.
list_jobs tracks every run of your pipelines. You see a history of all executed jobs, plus the success or failure status and the exact timestamps. list_connections pulls a complete list of every API and database connection your workflows use, letting you audit all your sources and destinations. You've got list_transformations to pull a catalog of every data mapping rule and transformation logic you've set up.
You can also check your usage with get_account, which gives you real-time metrics on your workspace credits and limits. This lets you manage your data processing budget as you go. You use these tools through your AI client, and it presents the structured data back to you in a natural conversation.
You just talk to your agent, and it gets you the raw facts about your data infrastructure. It's straightforward.
How Integrate.io MCP Works
- 1 Subscribe to the server and input your Integrate.io API Key.
- 2 Ask your AI client to perform an action (e.g., 'Show me the failure history for the last 3 jobs').
- 3 The agent calls the relevant tool (
list_jobs), and you get the structured data returned directly in the chat.
The bottom line is, you control your data infrastructure by talking to it, not by clicking through web portals.
Who Is Integrate.io MCP For?
Data Engineers who spend too much time switching tabs between dashboards to check job statuses. Analytics Leads who need to audit data transformations and connection mappings before running a major report. Operations Analysts who need to track account credit usage and pipeline run histories to optimize data integration workflows.
Uses list_jobs to monitor ETL job statuses and get_pipeline to verify configuration details without leaving their main workflow.
Uses list_connections and list_transformations to audit data integrity, ensuring that source data maps correctly to reporting requirements.
Uses get_account to track budget usage and list_jobs to optimize data integration workflows and identify failure patterns.
What Changes When You Connect
- Stop clicking through dashboards. Check the status of a job run or list all pipelines using
list_jobsorlist_pipelinesdirectly in your chat window. It saves time. - Validate data lineage instantly. Use
list_transformationsto inspect mapping logic and verify data quality rules without opening the web interface. - Maintain full visibility into your data sources.
list_connectionsshows every database and API target, making source auditing simple. - Track your budget in real-time.
get_accountgives you immediate access to workspace limits and remaining credits, keeping your data processing costs in check. - Deep dive into pipeline failures. When a job fails, use
get_pipelineto get the detailed schema and variables for that specific pipeline, helping you fix the root cause faster.
Real-World Use Cases
Investigating a failed data sync.
A data engineer notices the 'Customer Export' job failed. Instead of jumping to the dashboard, they ask their agent to run list_jobs to confirm the failure, and then call get_pipeline to inspect the specific pipeline's schema and variable definitions, pinpointing the source of the error.
Auditing data sources for compliance.
An analytics lead needs to know every database connected to the data warehouse. They ask their agent to run list_connections, which provides an exhaustive list of all APIs and databases, ensuring no unauthorized sources are feeding data.
Checking overall data flow scope.
A new team member needs to see what data is flowing through the system. They ask their agent to run list_pipelines to get a master list, and then use list_transformations to understand how the raw data is mapped before consumption.
Budget monitoring for a large project.
An operations analyst is running several large jobs. They ask their agent to run get_account to see current credit usage. This prevents the pipeline from failing mid-run due to hitting an unexpected usage limit.
The Tradeoffs
Manual Dashboard Jumps
The old way is clicking the main dashboard, finding the job history tab, clicking a specific job, then going to the connections tab, and finally cross-referencing the transformation rules. This takes 15-20 clicks and often misses context.
→
Use the agent to run list_jobs for history, then get_pipeline for details, and list_transformations for mapping. The agent stitches the data together for you.
Guessing API Endpoints
Trying to remember if the job status is under 'Runs' or 'History', or if the connection list is 'Source' or 'Target'. This leads to incorrect API calls and wasted time.
→
Just ask your agent. It knows to call list_jobs for run history and list_connections for the full list of sources.
Ignoring Account Limits
Running a massive, untested pipeline that fails halfway through because the workspace hits its credit limit, leading to unexpected data loss and billing surprises.
→
Always check get_account first. It tells you your remaining credits and limits before you start a big job.
When It Fits, When It Doesn't
Use this if you need to audit, monitor, or inspect the structure of your data pipeline (the 'what' and 'why'). You need to know why a job failed or how a piece of data got mapped. Don't use this if your only goal is to manually edit a setting or manually trigger a run—the server is for read-only visibility and reporting. If you just need to check if a pipeline exists, list_pipelines is enough. If you need to know if the pipeline is currently running, you need the combined view of list_jobs and get_pipeline. It's a deep diagnostic tool, not a quick status checker.
Independent Platform Disclaimer: Vinkius is an independent platform and is not affiliated with, endorsed by, sponsored by, verified by, or otherwise authorized by Integrate.io. All third-party trademarks, logos, and brand names are the property of their respective owners. Their use on this website is strictly for informational purposes to identify service compatibility and interoperability.
VINKIUS INFRASTRUCTURE
Cloud Hosted
Managed infra
V8 Isolated
Sandboxed per request
Zero-Trust Proxy
No stored credentials
DLP Enforced
Policy on every call
GDPR Compliant
EU data residency
Token Compression
~60% cost reduction
Works with Claude, ChatGPT, Cursor, and more
The Model Context Protocol standardizes how applications expose capabilities to LLMs. Instead of operating in isolation, your AI gains direct access to external platforms, live data, and real-world actions through secure, standardized connections.
This server provides 6 capabilities that interface natively with Claude, ChatGPT, Cursor, and any MCP client. No middleware. No custom integration required.
Available Capabilities
Checking data lineage shouldn't require 10 tabs and 5 clicks.
Today, finding out why a report is wrong means jumping from the BI dashboard to the ETL tool, then opening the job log, finding the job ID, then opening the connection manager to verify the credentials, and finally checking the transformation mapping document. It's a massive, manual context switch.
With this MCP server, you just ask your agent, 'Why did the 'Sales Data' job fail?' The agent calls `list_jobs` and `get_pipeline` in sequence, giving you the error, the failing schema, and the variables, all in one chat reply. It's immediate diagnosis.
Integrate.io MCP Server: Audit data connections and pipelines.
You used to manually export the connection list, cross-reference it with a spreadsheet, and then manually compare it against the list of active pipelines to see what was connected to what. This was slow and error-prone.
Now, you ask the agent to run `list_connections` and `list_pipelines`. The agent delivers a structured report showing exactly which data packages rely on which API endpoints. You see the dependency map instantly.
Common Questions About Integrate.io MCP
How do I use `list_jobs` to check if a pipeline ran successfully? +
Run list_jobs and look for the 'Success' status in the job history. The output shows the job name, the run time, and the status, letting you quickly verify successful runs.
What is the difference between `list_pipelines` and `list_jobs`? +
list_pipelines shows the definitions (the blueprints) of all your data packages. list_jobs shows the executions (the actual runs) of those pipelines over time.
How do I use `get_pipeline` to troubleshoot an error? +
Run get_pipeline and supply the specific pipeline ID. This retrieves the detailed schema, nodes, and variables for that pipeline, helping you see the structure that caused the failure.
Do I need to use `list_connections` if I check `get_pipeline`? +
No, they aren't redundant. get_pipeline shows the structure of the data flow; list_connections lists the external credentials and APIs the flow relies on. You need both for full context.
What is the best way to check my account spending with `get_account`? +
Simply ask the agent to run get_account. It returns your current workspace limits, remaining credits, and overall usage metrics, keeping your data processing budget visible.
How do I use `list_transformations` to audit data mapping logic? +
You use list_transformations to see every mapping rule defined in your account. This lets you verify the exact logic and data quality checks used when data moves from one source to another.
What should I do if a pipeline fails and I use `get_pipeline`? +
When get_pipeline returns failure details, check the job history using list_jobs. The job status logs will point to the specific error code or connection failure that caused the issue.
Is there a way to check account limits or credits using `get_account`? +
Yes, get_account provides real-time visibility into your workspace limits and remaining processing credits. This lets you manage your data processing budget before hitting a hard cap.
Can I see the exact logic of a data transformation through my agent? +
Yes. Use the list_transformations tool to retrieve the established data mappings in your account. This allows your agent to describe the transformation rules being applied to your data without you needing to open the Integrate.io UI.
How do I check if my last pipeline run was successful? +
The list_jobs tool provides a complete history of pipeline runs. Your agent will report the status (Success, Failed, Running) and duration of recent jobs, making it easy to monitor the health of your automated data flows.
Can my agent list all connected databases in my account? +
Absolutely. Use the list_connections tool to identify all source and destination targets, including Postgres, MySQL, Snowflake, and BigQuery instances currently linked to your data stack.
Use it with your favorite AI tools
Connect this server to Cursor, Claude, VS Code, and more.
More in this category

Elastic Enterprise Search
Manage enterprise search via Elastic — search engines and documents, handle indexing, and monitor search analytics directly from any AI agent.

Matillion (Cloud Data Integration & ELT)
Manage data pipelines via Matillion — audit ETL workflows, track execution statuses, and monitor cloud environments.
USDA FoodData Central
Access the gold standard in nutrition data — 300,000+ foods with scientific-grade nutrient profiles from the U.S. Department of Agriculture.
You might also like

Gong
Unlock revenue intelligence by analyzing calls, transcripts, and customer interactions.
Liaison
Centralize admissions and enrollment management for higher education with applicant tracking and document collection workflows.
EZO Asset Intelligence
Equip your AI agent to manage fixed assets, track inventory, and monitor checkouts via the EZO.io (EZOfficeInventory) API.