Replicate MCP. Run and manage thousands of ML model predictions.
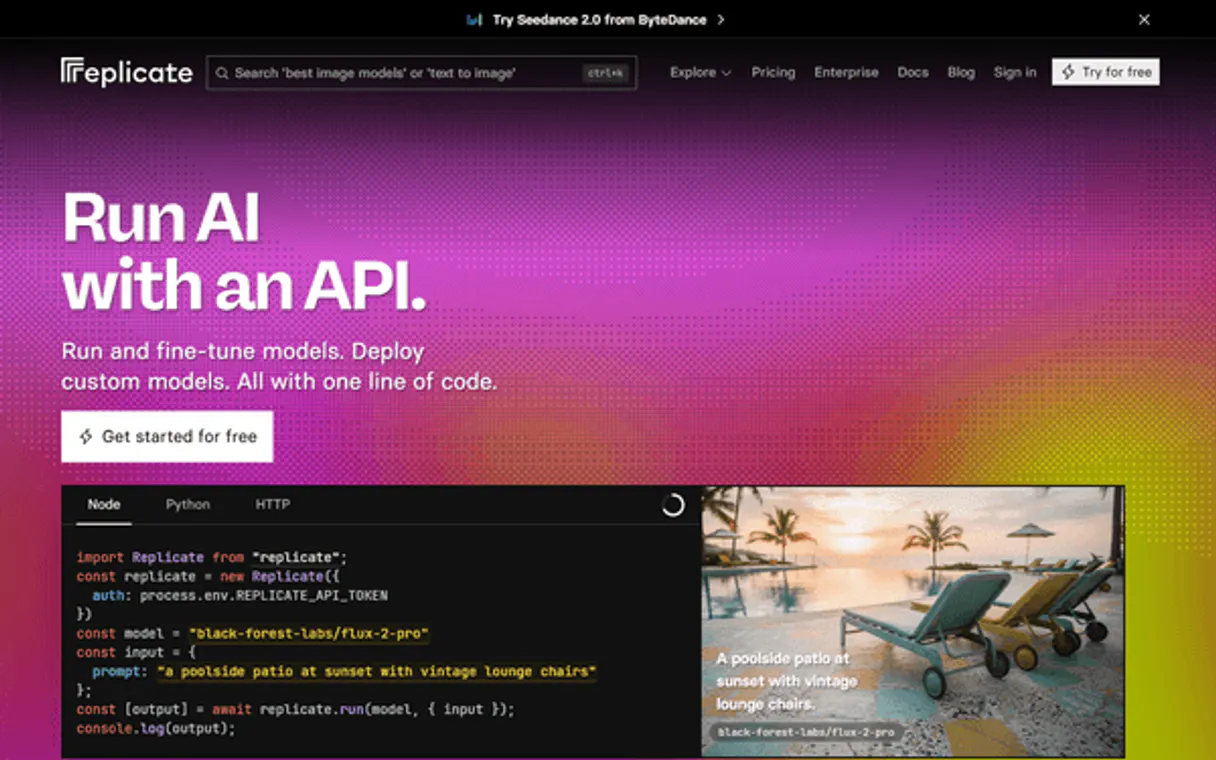
Replicate lets your AI agent access thousands of open-source machine learning models—for generating images, text, audio, and video. Instead of jumping between web dashboards or writing complex API calls, you talk to your agent, and it handles the entire ML lifecycle: finding a model, setting parameters, running the prediction, and retrieving the final result.
Give Claude and any AI agent real-world access
Your agent finds and details specific ML models by name or category.
You can list entire groups of related models, such as all text-to-image generators or all LLMs.
The agent verifies your token status and shows you current usage information.
You initiate a model run by providing the necessary input data to generate content.
The agent monitors running predictions, telling you when they start, process, fail, or finish.
You can view available GPU hardware options and list your prediction history.
Ask an AI about this
Waiting for input…
What AI agents can do with Replicate Alternative: 12 Tools for Model Operations
These twelve tools allow your AI client to manage the entire machine learning lifecycle, from discovering models to running predictions and tracking final results.
Make your AI actually useful.
Add this MCP to Claude, Cursor, or Windsurf and your AI stops guessing. It gets real tools to look things up, take action, and handle the stuff you keep doing by hand.
Start using Replicate MCPCancel Prediction
Stops an ML prediction that is currently running using its unique ID.
Create Prediction
Starts a new model run by sending the required inputs and specifying the target...
Get Account
Checks your API token status, showing your account type and usage limits.
Get Collection
Retrieves details for a specific group of models, like all audio-to-audio effects.
Get Model
Fetches detailed information about a single ML model using its full owner/name slug.
Get Model Versions
Lists all available versions for a specific model, including their IDs and required schemas.
Get Prediction
Retrieves the current status and final output data of any prediction using its ID.
List Collections
Shows all available model collections, grouping models by type (e.g., text-to-image).
List Hardware
Provides a list of available GPU hardware options and their pricing tiers.
List Models
Displays a broad catalog of every model, including run counts and required hardware.
List Predictions
Shows the history of your most recent runs, giving IDs, models, and status for...
Search Models
Narrows down the catalog to find specific types of models using a keyword query (e.g., 'music' or 'llm').
Security and governance baked right in.
Pick your AI client below to get set up. Just create a Vinkius account, subscribe, and you're instantly up and running. We handle the entire backend infrastructure, delivering out-of-the-box support for HTTPS Streamable, SSE, and OAuth2—zero messy routing required.
Claude AI
Open Claude Settings
Go to claude.ai, click your profile icon, then navigate to Customize → Connectors.
Add Custom Connector
Click the "+" button and select Add custom connector. Paste your Vinkius endpoint URL:
https://edge.vinkius.com/[YOUR_TOKEN_HERE]/mcp
Replace [YOUR_TOKEN_HERE] with your token
from cloud.vinkius.com. For OAuth-protected servers, expand
Advanced settings to add credentials.
Start a conversation
Open a new chat. The Replicate integration is available immediately — no restart needed.
Choose How to Get Started
Build a custom MCP for your own tools, or connect a ready-made integration from our catalog.
Build Your Own
Turn any API into an MCP. Import a spec, define Agent Skills, or deploy with MCPFusion.
- Import from OpenAPI, Swagger, or YAML specs
- Create Agent Skills with progressive disclosure
- Deploy to edge with MCPFusion framework
- Built in DLP, auth, and compliance on each call
- Real time usage dashboard and cost metering
- Publish to catalog or keep private
Make Your AI Do More
Start with Replicate, then connect any of our 5,200+ other servers whenever your AI needs more. One click, no limits.
- Use this MCP plus 5,200+ others, all in one place
- Add new capabilities to your AI anytime you want
- Connections are secured and governed automatically
- Track usage and costs across all your servers
- Works with Claude, ChatGPT, Cursor, and more
- New servers added to the catalog weekly
Independent Platform Disclaimer: Vinkius is an independent platform and is not affiliated with, endorsed by, sponsored by, verified by, or otherwise authorized by Replicate. All third-party trademarks, logos, and brand names are the property of their respective owners. Their use on this website is strictly for informational purposes to identify service compatibility and interoperability.
VINKIUS CLOUD
Cloud Hosted
Managed infra
V8 Isolated
Sandboxed per request
Zero-Trust Proxy
No stored credentials
DLP Enforced
Policy on each call
GDPR Compliant
EU data residency
Token Compression
~60% cost reduction
The friction points in ML prototyping today are brutal.
Right now, generating content with open-source AI models feels like a multi-tab web session. You check the Replicate website for available models; you copy complex slugs and schemas into your local script; then, to see if it worked, you have to wait until the prediction finishes, manually checking its status on another page.
With this MCP, all that complexity vanishes. Your agent handles the entire process conversationally: finding the model, submitting the data, and giving you a clear update when the content is ready. You just get the result.
Replicate MCP gives you full ML lifecycle control.
You no longer have to manually switch between discovery, execution, and status checking. Tools like `get_model` give you deep model details upfront; `create_prediction` runs the job; and `get_prediction` tracks the outcome—all within one conversation.
What's different now is that your AI client acts as a dedicated ML operations assistant, keeping track of everything so you can focus purely on what you want to create.
What Replicate MCP does for your AI
Your AI client connects directly to this MCP to treat open-source ML models like an internal service. You can ask your agent to find specific capabilities—like text-to-image generators or advanced LLMs—and it handles model discovery and selection across thousands of available options. Need to run something? Just tell your agent what you want, and it executes the prediction.
It tracks everything from 'starting' to 'succeeded', giving you a single conversation thread for complex ML operations. The whole process is abstracted away; you don't manage API keys or wait on status pages. All this power is housed within Vinkius, making Replicate an operational resource available through any MCP-compatible client.
019d8477-8851-70ce-8501-78d3fa84df45 How to set up Replicate MCP
The bottom line is you treat complex machine learning pipelines like simple conversational commands.
Subscribe to this MCP and provide your Replicate API Token.
Tell your AI agent what you need, like 'Generate a picture of a robot reading' or 'List all video models'.
The agent runs the necessary tool calls in the background, providing you with the status updates and final output links directly in your conversation.
Who uses Replicate MCP
The ML Engineer who needs to prototype dozens of models without touching the command line. The Developer who wants to build an AI application that generates content, not just text. The Researcher who needs to compare hardware requirements for multiple model types.
They use this MCP to compare different models by checking their required GPU hardware before deciding which one is cost-effective for a new project.
They integrate prediction status tracking into an application, using the agent to check if a generated image or audio file is ready without constant polling.
They use this MCP to quickly explore model collections and inspect version schemas for models they plan to test in a new environment.
Benefits of connecting Replicate MCP
Stop managing multiple websites. Instead of navigating the Replicate site to check status, you simply ask your agent for the prediction status using get_prediction or review history with list_predictions. It's all in one conversation.
You don't need to guess what models exist. Use search_models or list_collections to quickly discover everything available—from text-to-image generators to video processors—without leaving your chat window.
Model setup used to be a pain, requiring you to find the right version ID. Now, use get_model_versions to inspect the full schema and get the correct ID before running a prediction with create_prediction.
Managing costs is easier when you can check hardware options. Use list_hardware to see available GPU types and pricing tiers before launching any job, preventing expensive mistakes.
The ability to cancel jobs mid-stream is huge. If you realize the prompt was wrong after a few seconds, use cancel_prediction immediately instead of letting it run to completion.
Replicate MCP use cases
Creating an AI art campaign
A marketer needs 50 different fantasy images for a product launch. Instead of manually running fifty separate commands, they ask their agent to search for the best text-to-image model, run five variations, and track all the outputs using create_prediction and get_prediction.
Testing LLM performance
A developer needs to compare how three different Large Language Models (LLMs) handle a specific set of prompts. They use search_models to find the best candidates, then run multiple predictions, and finally review their usage logs using list_predictions.
Building an automated video pipeline
A content creator wants to turn a text description into a short video. They first check available hardware with list_hardware, select the right model, and run the prediction, ensuring they get all necessary status updates via get_prediction.
Debugging an ML pipeline
An ML engineer runs a batch of predictions but one fails. Instead of checking logs manually, they use list_predictions to see the failure ID and then check the details using get_prediction to understand why it failed.
Replicate MCP tradeoffs
What to watch out for, and the recommended way to handle each one.
Guessing model parameters
The user tries to run a prediction for an LLM but doesn't know if they need the owner/name format or what input schema is required, leading to immediate failure.
First, use get_model with the specific owner and name slug. This confirms the model exists and shows you its exact input requirements before attempting any prediction.
Ignoring usage costs
A developer runs multiple image generation jobs back-to-back without knowing if they are using a powerful, expensive GPU cluster, resulting in unexpected billing.
Always check available hardware and pricing first by running list_hardware. This gives you the cost context needed to plan your workload before calling create_prediction.
Treating ML like simple APIs
The user expects a single command to instantly return all results. Since models take time (10-60 seconds), the prediction will fail if not checked later.
After create_prediction, you must use get_prediction periodically. This tool is designed specifically for checking status and retrieving final results once they are ready.
When to use Replicate MCP
Use this MCP if your primary bottleneck is the operational complexity of running ML models, not the creativity itself. Specifically, if you need to discover thousands of tools (models), manage their lifecycle (creation, tracking, cancellation), or compare resource needs (hardware/versions) before execution. You'll use it if your workflow involves a sequence: Search -> Select Model/Version -> Run Prediction -> Check Status.
Don't use this MCP if you just need to list model names; list_models handles that simply. Also, don't use it if you are only trying to understand the general concept of generative AI—that requires reading documentation, not running code. If your goal is purely resource management (like billing reports), look for dedicated accounting services instead.
Frequently asked questions about Replicate MCP
How do I find out what models are available in Replicate using the Replicate MCP? +
Use list_models to get a broad overview of every model. For more focused results, try search_models, which lets you narrow down by keywords like 'llm' or 'video'.
What if my prediction fails? How do I check the error details with Replicate MCP? +
Use get_prediction and provide the failed ID. This tool returns logs and status information, helping you diagnose whether the failure was due to bad input or a model issue.
Does the Replicate MCP help me manage costs? +
Yes. Before running any job, check available options using list_hardware to see GPU types and associated pricing for your prediction workload.
Can I run a model if I don't know the exact version ID? (Replicate MCP) +
No. To ensure compatibility, you must first use get_model_versions to find all versions of the model and select the correct 64-character hash ID for create_prediction.
What is the difference between `list_models` and `search_models` on the Replicate MCP? +
list_models gives you a full directory of everything. search_models lets you filter that massive catalog based on specific keywords, making discovery much faster.