Better Stack MCP for AI Agents. Manage uptime, track incidents, and control on-call scheduling
Better Stack automates incident response and uptime monitoring. Connect your Better Stack account to any AI client so it can act as a Level 1 SRE, diagnosing downtime, checking monitor status, and managing escalations through natural conversation.
Give Claude and any AI agent real-world access
Retrieves a comprehensive list of every uptime monitor configured in Better Stack.
Fetches the full technical definition and status for any single monitoring check, like HTTP pings or latency rules.
Provides a list of all known or active outages currently recorded in Better Stack.
Pulls the full, detailed history and root cause payload for a specific reported outage.
Flags an active system incident as acknowledged in Better Stack, temporarily stopping automated paging alerts.
Manually sets a specific reported outage to a resolved state within the monitoring platform.
Lists all passive heartbeats and background worker checks to ensure core system processes are running correctly.
Reads the configuration details for public-facing status dashboards across your global infrastructure.
Retrieves current active shifts and team rotation calendars to identify who is responsible right now.
Ask an AI about this
Waiting for input…
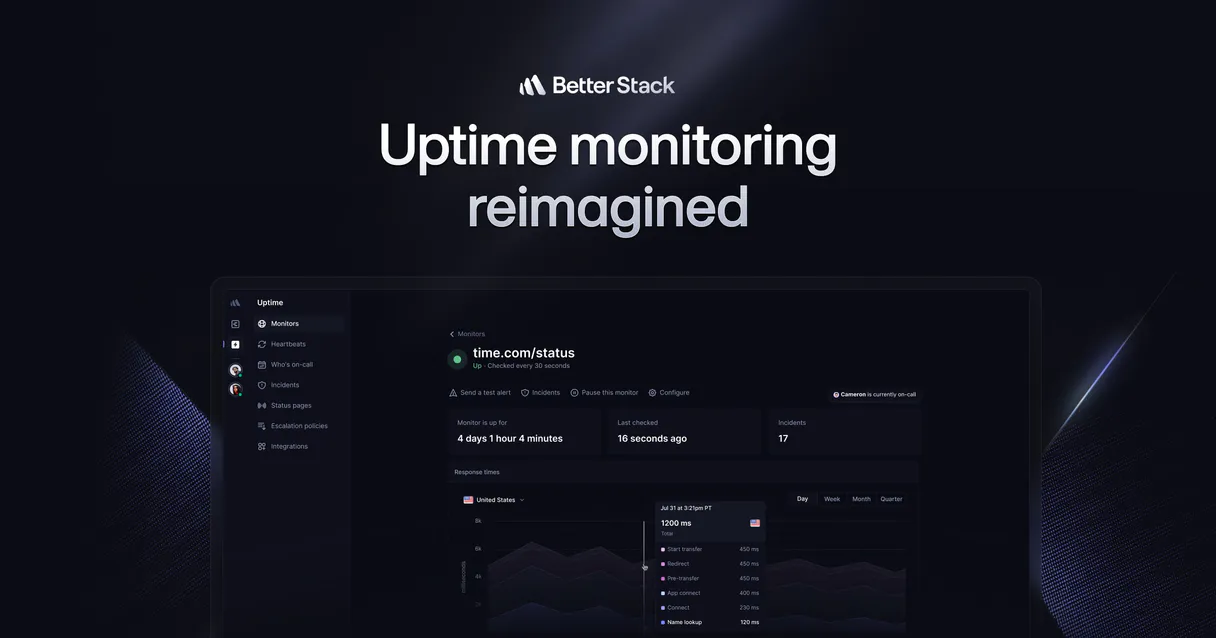
What AI agents can do with Better Stack: 10 Tools for Incident Management & Uptime Monitoring
Use these specific tools to list monitors, retrieve incident timelines, acknowledge alerts, view on-call schedules, and check background worker heartbeats.
Make your AI actually useful.
Add this MCP to Claude, Cursor, or Windsurf and your AI stops guessing. It gets real tools to look things up, take action, and handle the stuff you keep doing by hand.
Start using Better Stack MCPList Monitors
Lists all uptime monitors configured in Better Stack.
Get Monitor
Retrieves specific details for one monitor, like its ping type or latency rules.
List Incidents
Gets a list of all explicitly reported system incidents.
Get Incident
Fetches the full technical payload and timeline for a specific incident.
Acknowledge Incident
Changes the status of an ongoing incident to 'acknowledged' in Better Stack, which...
Resolve Incident
Forces a specific reported outage into a resolved state within the monitoring system.
List Heartbeats
Lists all passive tracking endpoints and cron jobs used to validate background worker status.
Get Heartbeat
Pulls explicit technical details about a single, passive heartbeat check.
List Status Pages
Lists all configured public-facing status pages for your global services.
List On Call
Retrieves the current on-call team schedules and routing calendars.
Security and governance baked right in.
Pick your AI client below to get set up. Just create a Vinkius account, subscribe, and you're instantly up and running. We handle the entire backend infrastructure, delivering out-of-the-box support for HTTPS Streamable, SSE, and OAuth2—zero messy routing required.
Claude AI
Open Claude Settings
Go to claude.ai, click your profile icon, then navigate to Customize → Connectors.
Add Custom Connector
Click the "+" button and select Add custom connector. Paste your Vinkius endpoint URL:
https://edge.vinkius.com/[YOUR_TOKEN_HERE]/mcp
Replace [YOUR_TOKEN_HERE] with your token
from cloud.vinkius.com. For OAuth-protected servers, expand
Advanced settings to add credentials.
Start a conversation
Open a new chat. The Better Stack MCP for AI Agents integration is available immediately — no restart needed.
Choose How to Get Started
Build a custom MCP for your own tools, or connect a ready-made integration from our catalog.
Build Your Own
Turn any API into an MCP. Import a spec, define Agent Skills, or deploy with MCPFusion.
- Import from OpenAPI, Swagger, or YAML specs
- Create Agent Skills with progressive disclosure
- Deploy to edge with MCPFusion framework
- Built in DLP, auth, and compliance on each call
- Real time usage dashboard and cost metering
- Publish to catalog or keep private
Make Your AI Do More
Start with Better Stack, then connect any of our 5,200+ other servers whenever your AI needs more. One click, no limits.
- Use this MCP plus 5,200+ others, all in one place
- Add new capabilities to your AI anytime you want
- Connections are secured and governed automatically
- Track usage and costs across all your servers
- Works with Claude, ChatGPT, Cursor, and more
- New servers added to the catalog weekly
Independent Platform Disclaimer: Vinkius is an independent platform and is not affiliated with, endorsed by, sponsored by, verified by, or otherwise authorized by Better Stack. All third-party trademarks, logos, and brand names are the property of their respective owners. Their use on this website is strictly for informational purposes to identify service compatibility and interoperability.
VINKIUS CLOUD
Cloud Hosted
Managed infra
V8 Isolated
Sandboxed per request
Zero-Trust Proxy
No stored credentials
DLP Enforced
Policy on each call
GDPR Compliant
EU data residency
Token Compression
~60% cost reduction
Better Stack MCP for AI Agents: Automated Incident Triage and Uptime Monitoring
Right now, when a critical service goes down, your workflow is manual hell. You open the monitoring dashboard to check pings, then switch to an incident management tool to see if it’s already recorded. Then you might jump to a calendar system just to figure out who is on call—all while trying not to lose track of which tab showed the real root cause. It's slow, and context switching kills your focus.
With this MCP, your agent handles all that cross-platform legwork for you. You simply ask your AI client what’s wrong, and it uses tools like list_incidents and get_incident to pull together a complete diagnosis from multiple sources instantly. You get an actionable summary, not just links to dashboards.
Better Stack MCP for AI Agents: Controlling On-Call Schedules and Escalations
Before this, determining who was supposed to be on call often involved checking a separate Google Sheet or an internal wiki page. If the sheet wasn't updated, you wasted time calling the wrong people, delaying resolution.
Now, your agent uses list_on_call to check the official routing calendars directly. This eliminates guesswork and ensures that when an alert fires, everyone knows precisely who is primary responder right now.
What Better Stack MCP for AI Agents MCP does for your AI
This MCP lets your AI agent function like an on-call engineer, letting you manage critical system alerts without leaving your chat window. Instead of jumping between monitoring dashboards and terminal sessions during an outage, your agent handles the initial triage. It can check which monitors are failing—whether it's a simple HTTP endpoint ping or a complex DNS probe.
If there’s an active issue, the AI finds all firing incidents, checks their full timelines, and even lets you acknowledge them to stop the paging cascade. The agent also tracks who is currently scheduled on call so you know exactly who to talk to next. Connecting this through Vinkius means your preferred AI client can access hundreds of other tools too, giving you a complete operational picture right where you work.
019d755b-724f-73b1-9dbc-ee8184a178fe How to set up Better Stack MCP for AI Agents MCP
The bottom line is that it gives your AI client a single, conversational point of entry to manage complex operational alerts across multiple systems.
Connect your Better Stack API token through Vinkius, granting your AI client the necessary permissions.
Tell your agent what you need: for instance, 'Show me all active incidents' or 'Who is on call today?'
The agent runs the appropriate tool and delivers the actionable data directly in conversation.
Who uses Better Stack MCP for AI Agents MCP
DevOps engineers and SREs who spend their nights jumping between dashboards desperately need this. If you're the ops engineer tired of manually checking ten different monitoring tools at 2 AM, this MCP saves your sanity.
Uses this to audit on-call matrices and orchestrate initial debugging workflows by pulling incident timelines or resolving dormant alerts without leaving the chat.
Runs checks like listing heartbeats and monitoring status pages to rapidly debug failing background workers while simultaneously patching code in a controlled environment.
Reviews recent downtime timelines or acknowledges critical alerts quickly so they can provide accurate updates to stakeholders without deep technical knowledge.
Benefits of connecting Better Stack MCP for AI Agents MCP
Stop switching context during an outage. Your agent handles incident triage—listing active incidents or inspecting monitor details—all without you leaving the chat.
Quickly determine who needs to be paged. You can pull active shifts and team schedules using the list_on_call tool, so you instantly know who's responsible for a failing system component.
Reduce alert fatigue and noise. By acknowledging an incident (acknowledge_incident) or forcing it resolved (resolve_incident), your agent controls the severity of notifications automatically.
Deep dive into failures without logging in. Need to audit why something broke? Use get_incident to pull the full technical timeline payload for any reported issue.
Verify background services immediately. The list_heartbeats tool lets you check passive tracking endpoints, ensuring critical workers haven't silently failed.
Maintain public transparency while debugging privately. You can read configured status pages (list_status_pages) to ensure customers see accurate information regardless of the current incident.
Better Stack MCP for AI Agents MCP use cases
The API endpoint is throwing 502 errors.
A developer asks their agent, 'Why is our main API failing?' The agent responds by listing monitors and uses get_monitor to pinpoint the exact HTTP endpoint ping that's failing. It then checks the incident timeline (get_incident) to find the root cause in minutes.
It's 3 AM and nothing is working.
The on-call engineer asks, 'Who should I talk to about this downtime?' The agent uses list_on_call to confirm John Doe is currently paged in Level 1. This saves them from wasting time checking old rotation schedules.
We need to update the incident report.
An engineering manager asks, 'What happened with Incident #8012?' The agent retrieves the detailed timeline payload using get_incident, providing all necessary logs and status changes for a comprehensive post-mortem.
We have background workers that might be failing.
A backend developer asks, 'Check our cron jobs.' The agent calls list_heartbeats, verifying that all passive tracking endpoints are reporting green. If one is down, they get the specific details via get_heartbeat to start patching.
Better Stack MCP for AI Agents MCP tradeoffs
What to watch out for, and the recommended way to handle each one.
Checking status manually
Copying and pasting URLs into ten separate monitoring dashboards or opening a dozen tabs during an outage. This wastes time, causes context switching, and misses the full picture.
Ask your agent to list_monitors first to see everything at once. Then use get_monitor on any specific service you need details for. Better Stack manages all of this in one chat.
Ignoring scheduled rotations
Calling multiple team members sequentially when an incident happens, wasting time determining who is actually responsible at that exact moment.
Use the list_on_call tool. This instantly tells you which team member or rotation calendar dictates who has primary ownership right now.
Confusing alerts with actual incidents
Treating a simple warning notification as a major outage, leading to unnecessary escalation and false alarms.
Always start by listing_incidents. This separates minor warnings from confirmed, active outages that require immediate action.
When to use Better Stack MCP for AI Agents MCP
Use this MCP if your primary pain point is context switching during system outages or needing a single source of truth for uptime status. If you frequently find yourself opening multiple tabs—one for monitoring, one for schedules, and another for incident timelines—this tool is essential because it groups all that data into conversational tools like list_monitors and get_incident.
Don't use this if your team needs to manage ticketing system workflows (like Jira or Zendesk). For those, you need a dedicated CRM integration MCP. If your goal is just running scheduled reports without real-time incident response, consider an API wrapper tool instead of the full Better Stack suite.
Frequently asked questions about Better Stack MCP for AI Agents MCP
How can I use the Better Stack MCP for AI Agents to check if my service is down? +
You ask your agent to list all monitors. It will give you a clean breakdown of every single uptime check, showing which HTTP endpoints or DNS probes are currently failing so you know exactly where the problem lies.
Can I use the Better Stack MCP for AI Agents to find out who is on call right now? +
Yes. Your agent uses the list_on_call tool to pull up the active rotation calendars. You'll get a clear name and role, so you don't waste time calling people outside their shift.
What if I want to know why an old incident happened? +
You can ask your agent about specific incidents using the tool that retrieves the full timeline payload. It pulls all the historical data, including error codes and timestamps, so you have everything for a post-mortem report.
Does the Better Stack MCP for AI Agents help me stop constant notifications? +
Absolutely. If an incident is confirmed or if it's already been addressed, your agent can acknowledge_incident or resolve_incident to manage the alert status and prevent unnecessary paging.
Does this MCP work for multiple services? Like my front end AND back end? +
Yes. It manages all monitors across your entire fleet, whether they are tracking HTTP endpoints or background cron heartbeats. You get one view of everything connected to Better Stack.