Bring Mlops
to LangChain
Create your Vinkius account to connect NVIDIA NIM to LangChain and start using all 8 AI tools in minutes. Fully managed, enterprise secure, and ready to use without writing a single line of code. No hosting, no server setup — just connect and start using.
Compatible with every major AI agent and IDE
 Gemini
Gemini
What is the NVIDIA NIM MCP Server?
What you can do
Take complete proxy command over physically hosted NIM limits checking analytics gracefully explicitly across local GPUs:
- Track Hardware Executions natively reading active telemetry resolving explicitly limits dynamically
- Extract Native Profiling determining exactly implicit LLMs mapping currently logically loaded securely
- Check Execution Bounds resolving liveness checking physically bound proxy nodes gracefully
- Map GPU Variables catching constraints logging strictly logical memory parameters efficiently
- Execute Host Audits asserting physical bounds securely over explicitly natively mounted docker endpoints
How it works
- Target the Ingress, explicitly coupling limits matching dynamically over the
NVIDIA_NIM_URLsafely mapping local instances - Pass Strict Logic Metrics, asserting native proxy queries exploring cleanly hardware latencies via Prometheus endpoints natively
- Map and execute hardware limits implicitly navigating explicitly resolving diagnostic errors routing strictly native proxy checks
Who is this for?
Explicitly targeted for MLOps Engineers, Hardware Proxies Admins, and Infrastructure Integrators dynamically orchestrating native NVIDIA chips securely.
Built-in capabilities (8)
Execute liveness probes natively evaluating if the physical host container orchestrator is responsive
Detect if the GPU inference layers have successfully loaded the explicitly configured model artifacts natively
Fetch explicit execution parameters catching native stdout proxies bound cleanly to the orchestrator layer securely
Parse explicit GPU topological limits mapped onto the NIM proxy securely formatting active hardware memory variables cleanly
Pull logical engine execution metrics mapping exactly the loaded foundational configuration bounds natively secure
Extract Prometheus hardware scaling metrics explicitly from the NIM orchestrator natively
Dump explicit active LLMs securely allocating inference targets over the logical backend array cleanly
Dynamically orchestrate bounds adjusting native hardware replication proxy assignments scaling execution layers
Why LangChain?
LangChain's ecosystem of 500+ components combines seamlessly with NVIDIA NIM through native MCP adapters. Connect 8 tools via Vinkius and use ReAct agents, Plan-and-Execute strategies, or custom agent architectures. with LangSmith tracing giving full visibility into every tool call, latency, and token cost.
- —
The largest ecosystem of integrations, chains, and agents. combine NVIDIA NIM MCP tools with 500+ LangChain components
- —
Agent architecture supports ReAct, Plan-and-Execute, and custom strategies with full MCP tool access at every step
- —
LangSmith tracing gives you complete visibility into tool calls, latencies, and token usage for production debugging
- —
Memory and conversation persistence let agents maintain context across NVIDIA NIM queries for multi-turn workflows
NVIDIA NIM in LangChain
Why run NVIDIA NIM with Vinkius?
The NVIDIA NIM connection runs on our fully managed, secure cloud infrastructure. We handle the hosting, maintenance, and security so you don't have to deal with servers or code. All 8 tools are ready to work instantly without any complex setup.
You stay in complete control of your data. Your AI only accesses the information you approve, keeping your sensitive passwords and private details completely safe. Plus, with automatic optimizations, your AI works faster and more efficiently.
* Every connection is hosted and maintained by Vinkius. We handle the security, updates, and infrastructure so you don't have to write code or manage servers. See our infrastructure
Over 4,000 integrations ready for AI agents
Explore a vast library of pre-built integrations, optimized and ready to deploy.
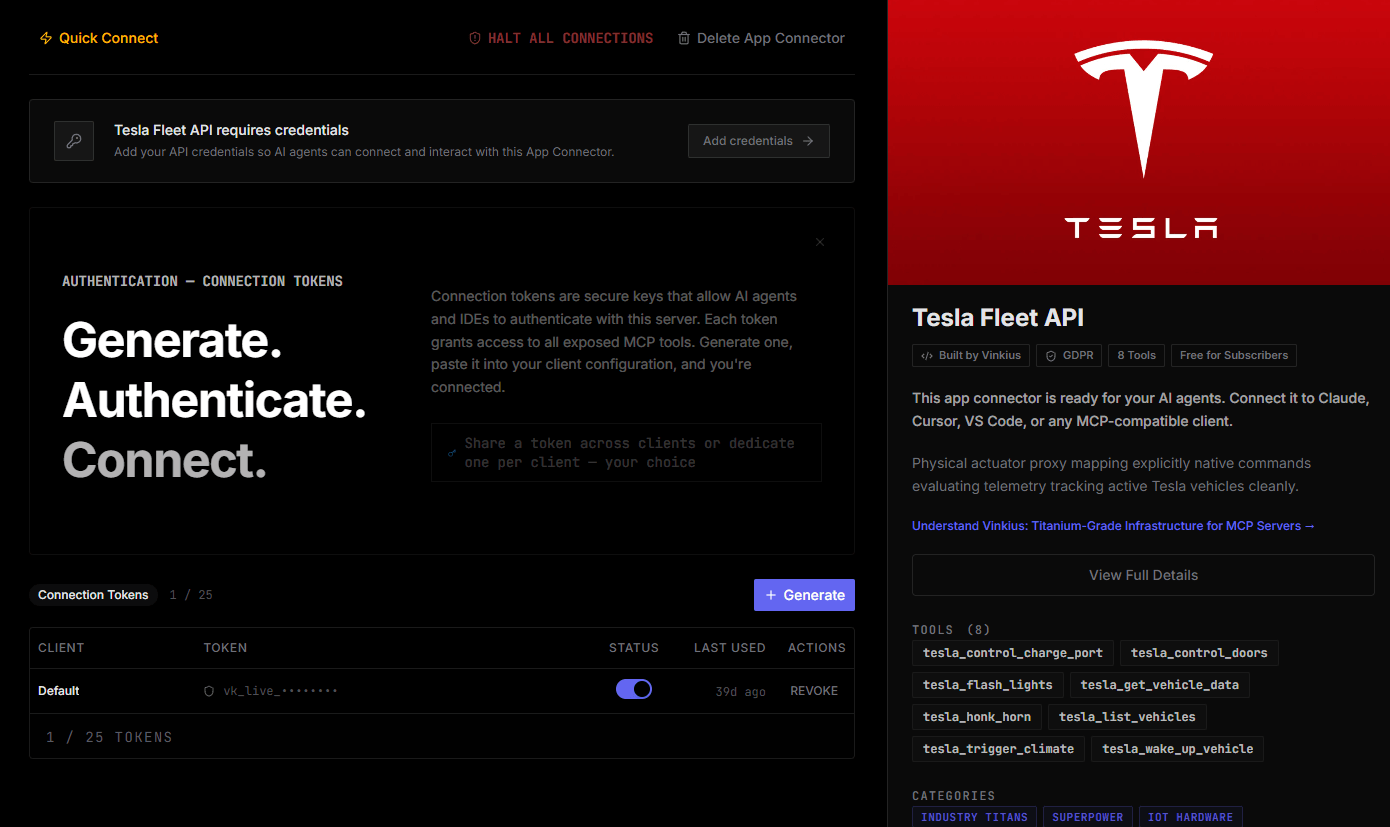
Connect securely in under 30 seconds
Generate tokens to authenticate and link external services in a single step.
Complete visibility into every agent action
Audit live requests, latency, success rates, and active security compliance policies.
Optimize spending and track token ROI
Analyze real-time token consumption and cost metrics detailed by connection.
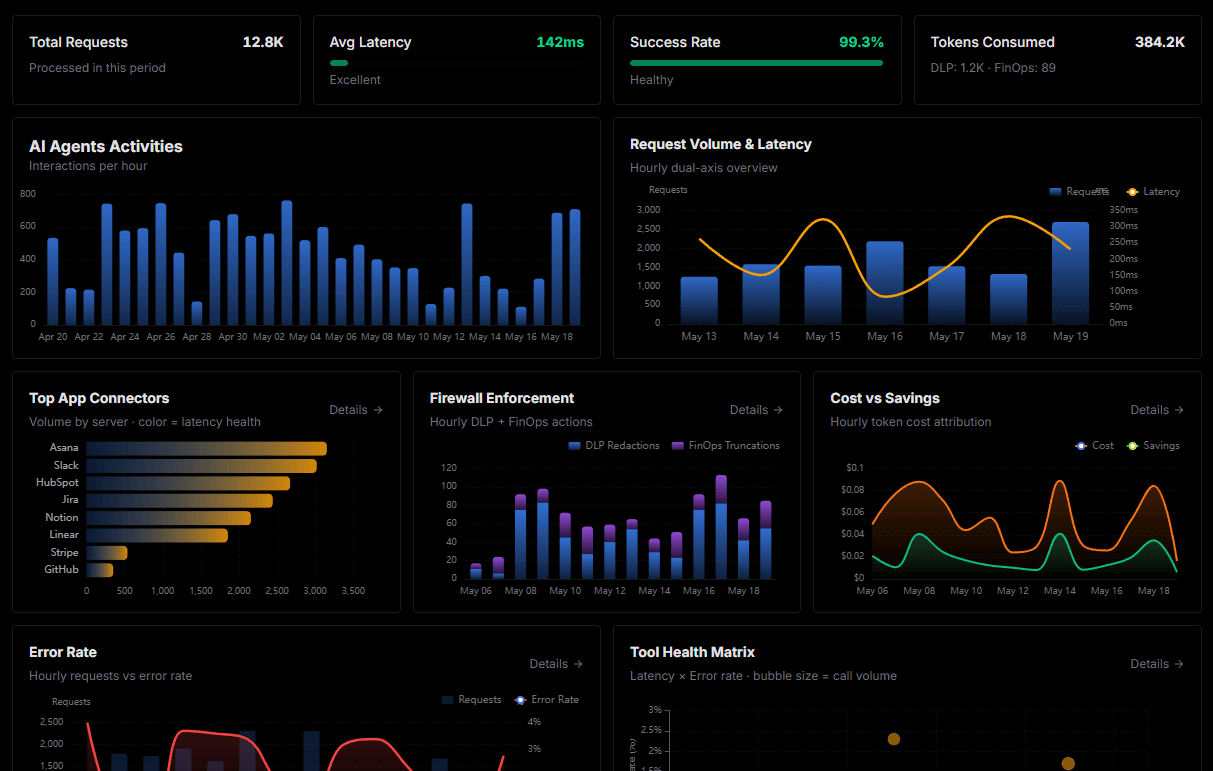
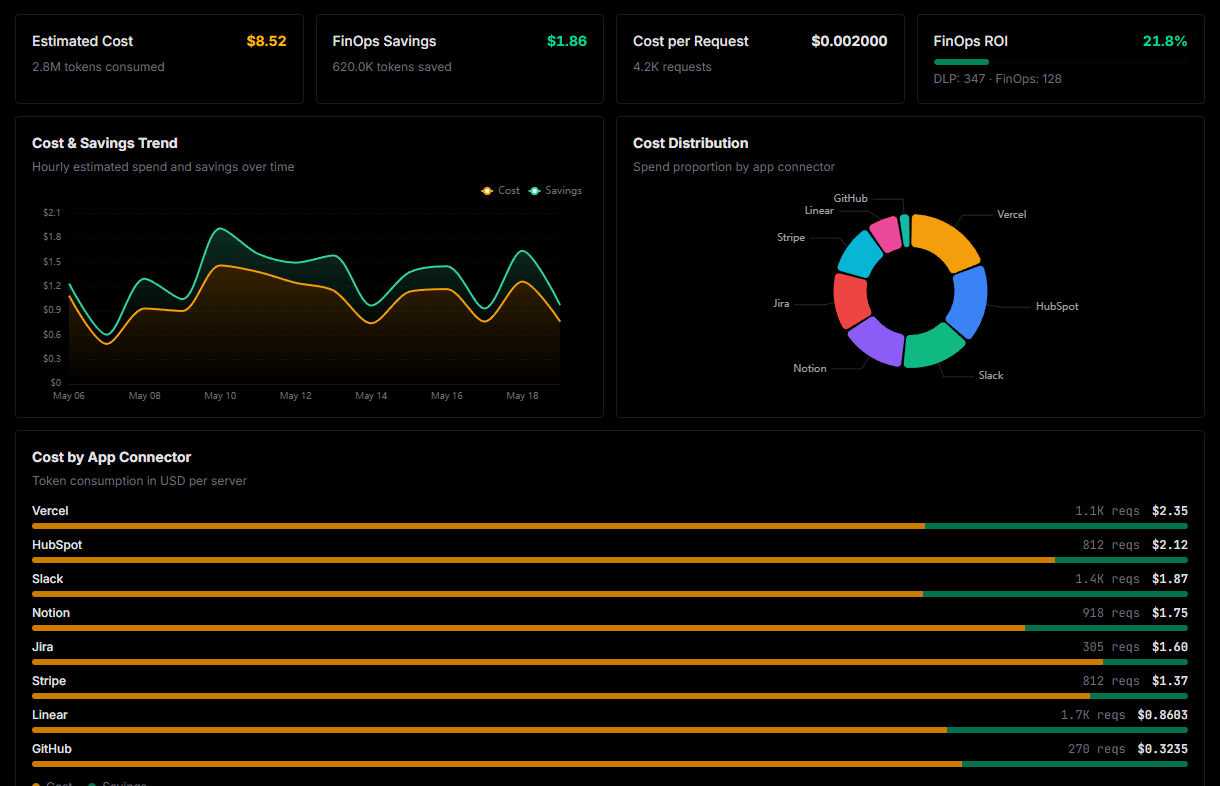
Explore our live AI Agents Analytics dashboard to see it all working
This dashboard is included when you connect NVIDIA NIM using Vinkius. You will never be left in the dark about what your AI agents are doing with your tools.
NVIDIA NIM and 4,000+ other AI tools. No hosting, no code, ready to use.
Professionals who connect NVIDIA NIM to LangChain through Vinkius don't need to write code, manage servers, or worry about security. Everything is pre-configured, secure, and runs automatically in the background.
Raw MCP | Vinkius | |
|---|---|---|
| Ready-to-use MCPs | Find and configure each manually | 4,000+ MCPs ready to use |
| Connection Setup | Manual coding & server setup | 1-click instant connection |
| Server Hosting | You host it yourself (needs 24/7 uptime) | 100% hosted & managed by Vinkius |
| Security & Privacy | Stored in plaintext config files | Bank-grade encrypted vault |
| Activity Visibility | Blind execution (no logs or tracking) | Live dashboard with real-time logs |
| Cost Control | Runaway AI token spend risk | Automatic budget limits |
| Revoking Access | Must delete files or code to stop | 1-click disconnect button |
How Vinkius secures
NVIDIA NIM for LangChain
Every request between LangChain and NVIDIA NIM is protected by our secure gateway. We automatically keep your sensitive data private, prevent unauthorized access, and let you disconnect instantly at any time.
Frequently asked questions
Can I explicitly track GPU hardware analytics natively using the NIM MCP integration?
Yes! Utilize get_metrics exposing Prometheus-compatible proxy limits tracking explicit hardware latencies easily natively securely.
How do I explicitly evaluate if my container instances mapped properly loaded native Foundation Models?
Target UUID probes natively mapped executing check_health_ready verifying bounds catching limits generating exact readiness states cleanly.
Does this call inference proxies executing completions bounds mapped dynamically?
No, this is infrastructure proxy bounding explicitly container node management. Utilize nvidia-catalog-mcp enforcing natively hosted inference bounds efficiently.
How does LangChain connect to MCP servers?
Use langchain-mcp-adapters to create an MCP client. LangChain discovers all tools and wraps them as native LangChain tools compatible with any agent type.
Which LangChain agent types work with MCP?
All agent types including ReAct, OpenAI Functions, and custom agents work with MCP tools. The tools appear as standard LangChain tools after the adapter wraps them.
Can I trace MCP tool calls in LangSmith?
Yes. All MCP tool invocations appear as traced steps in LangSmith, showing input parameters, response payloads, latency, and token usage.
MultiServerMCPClient not found
Install: pip install langchain-mcp-adapters
Explore More MCP Servers
View all →
JustCall
10 toolsManage phone calls, SMS, and recordings via JustCall API.

AntEater
10 toolsMonitor website changes, detect content updates, and receive alerts when key pages are modified across your digital properties.

Business Timezone & Holiday Scheduler
2 toolsEradicate LLM scheduling errors. Calculate exact business days skipping global public holidays and convert precise timezones flawlessly.

SQL Syntax Validator
1 toolsAudit SQL queries for syntax errors before executing them. Prevent DB crashes and deadlocks with local AST parsing.