Bring Telemetry
to LlamaIndex
Create your Vinkius account to connect Tesla Fleet API to LlamaIndex and start using all 8 AI tools in minutes. Fully managed, enterprise secure, and ready to use without writing a single line of code. No hosting, no server setup — just connect and start using.
Compatible with every major AI agent and IDE
 Gemini
Gemini
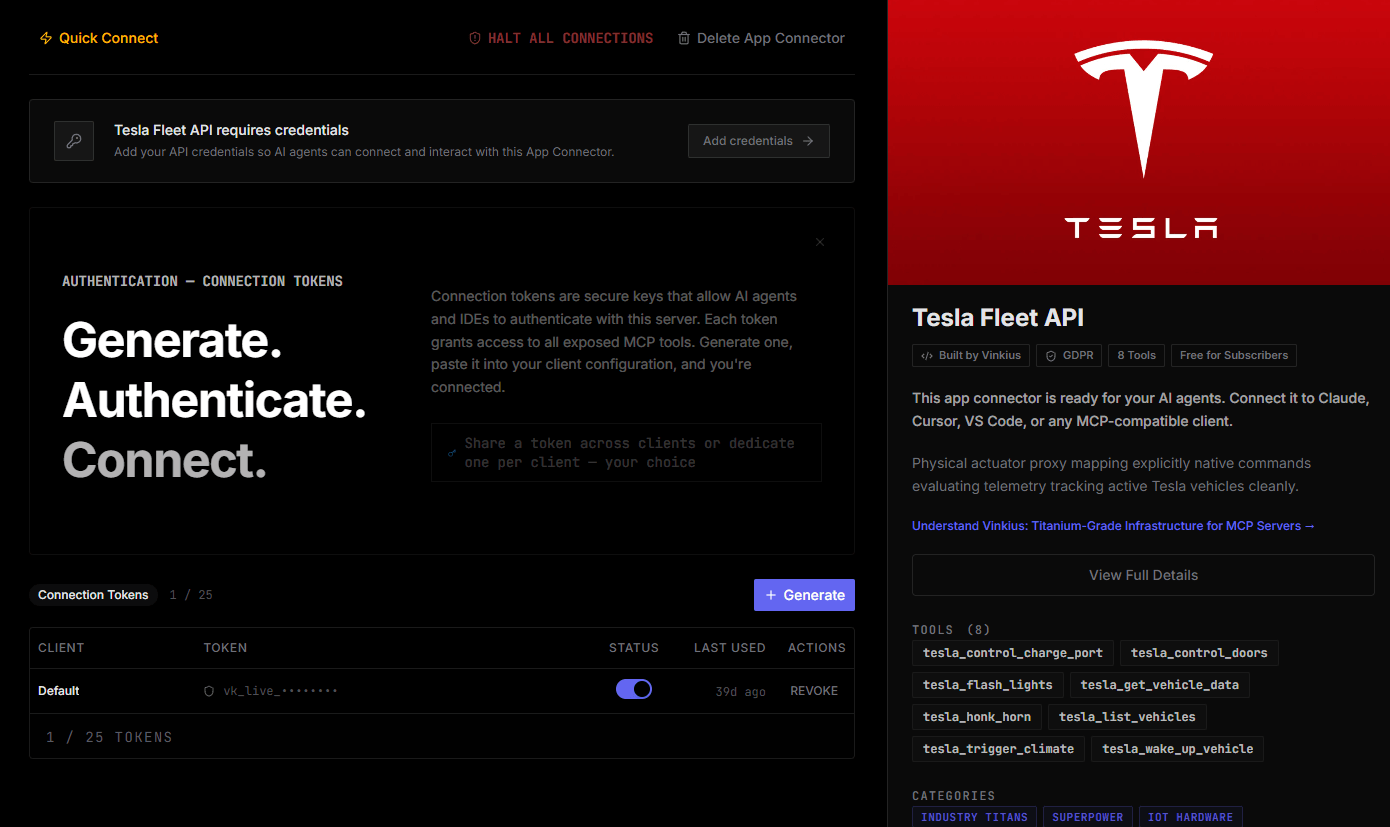
What is the Tesla Fleet API MCP Server?
What you can do
Take absolute proxy command over physically hosted Tesla vehicle hardware limits checking telemetries gracefully inside the Fleet Operator logic:
- Track Hardware Executions natively reading deep telemetry pulling explicitly GPS, Battery SoC, and Tire Pressures
- Execute Physical Relays actuating explicitly hardware limits bounding specific locks and interior HVAC bounds
- Wake Sleeping Vehicles directly triggering native relays catching cars in idle execution states parsing cleanly
- Manage Fleet Commands bounding honk and headlight mechanisms resolving completely natively safe locating structures
⚠️ CRITICAL WARNING: VEHICLE SLEEP STATE (HTTP 408)
To conserve the high-voltage battery limits, Tesla vehicles physically sever their continuous network proxy when parked. If you execute a read (like get_vehicle_data) or a mechanical command (like control_doors) while the car is sleeping, the API will natively return HTTP 408 Timeout.
The AI Agent MUST ALWAYS first invoke wake_up_vehicle, wait 10-15 seconds, and ONLY THEN route explicit subsequent logic telemetry proxies securely natively!
How it works
- Define the Regional Proxy, actively isolating endpoints correctly mapping your localized boundary (e.g.
nafor North America) - Engage Fleet Tokens, pulling
TESLA_FLEET_TOKENverifying cleanly limits inside the B2B configuration - Map and execute hardware navigating explicitly safely parsing latency errors bounding mechanically cleanly routing
Who is this for?
Specifically built for Fleet Managers, Automotive Logistics Engineers, and Enterprise Operators managing explicit Tesla vehicle matrices.
Built-in capabilities (8)
Call wake_up securely first executing correctly. Engage explicitly the charging port relay actively isolating the power array bounds smoothly
Wake up first safely implicitly executing physical relays. Actuate literal physical lock parameters securing or bounding native access inside the vehicle reliably
Use tesla_wake_up_vehicle first resolving safely. Trigger physical external headlight flash mechanisms securely bounding locating target implicitly
You MUST use tesla_wake_up_vehicle FIRST and wait before polling. Extracts master telemetry matrices fetching explicitly SoC battery, Odometer, exact GPS coordinates, and vehicle internal temperatures
Use tesla_wake_up_vehicle first bounding cleanly safely executing. Actuate the physical hardware horn mechanism remotely triggering a loud alert locating the fleet proxy actively
Dumps explicit physical vehicle structs enumerating the exact active fleet array native list
Trigger explicit wake_up first parsing. Engage explicitly the internal auto-conditioning climate system cleanly resolving temperature states before arrival
Wait 10 seconds explicitly after calling this. CRITICAL FIRST STEP: Trigger Explicit ignition matrices asserting the physical vehicle wakes from idle sleep states bounding actively over SaaS proxies
Why LlamaIndex?
LlamaIndex agents combine Tesla Fleet API tool responses with indexed documents for comprehensive, grounded answers. Connect 8 tools through Vinkius and query live data alongside vector stores and SQL databases in a single turn. ideal for hybrid search, data enrichment, and analytical workflows.
- —
Data-first architecture: LlamaIndex agents combine Tesla Fleet API tool responses with indexed documents for comprehensive, grounded answers
- —
Query pipeline framework lets you chain Tesla Fleet API tool calls with transformations, filters, and re-rankers in a typed pipeline
- —
Multi-source reasoning: agents can query Tesla Fleet API, a vector store, and a SQL database in a single turn and synthesize results
- —
Observability integrations show exactly what Tesla Fleet API tools were called, what data was returned, and how it influenced the final answer
Tesla Fleet API in LlamaIndex
Why run Tesla Fleet API with Vinkius?
The Tesla Fleet API connection runs on our fully managed, secure cloud infrastructure. We handle the hosting, maintenance, and security so you don't have to deal with servers or code. All 8 tools are ready to work instantly without any complex setup.
You stay in complete control of your data. Your AI only accesses the information you approve, keeping your sensitive passwords and private details completely safe. Plus, with automatic optimizations, your AI works faster and more efficiently.
* Every connection is hosted and maintained by Vinkius. We handle the security, updates, and infrastructure so you don't have to write code or manage servers. See our infrastructure
Over 4,000 integrations ready for AI agents
Explore a vast library of pre-built integrations, optimized and ready to deploy.
Connect securely in under 30 seconds
Generate tokens to authenticate and link external services in a single step.
Complete visibility into every agent action
Audit live requests, latency, success rates, and active security compliance policies.
Optimize spending and track token ROI
Analyze real-time token consumption and cost metrics detailed by connection.
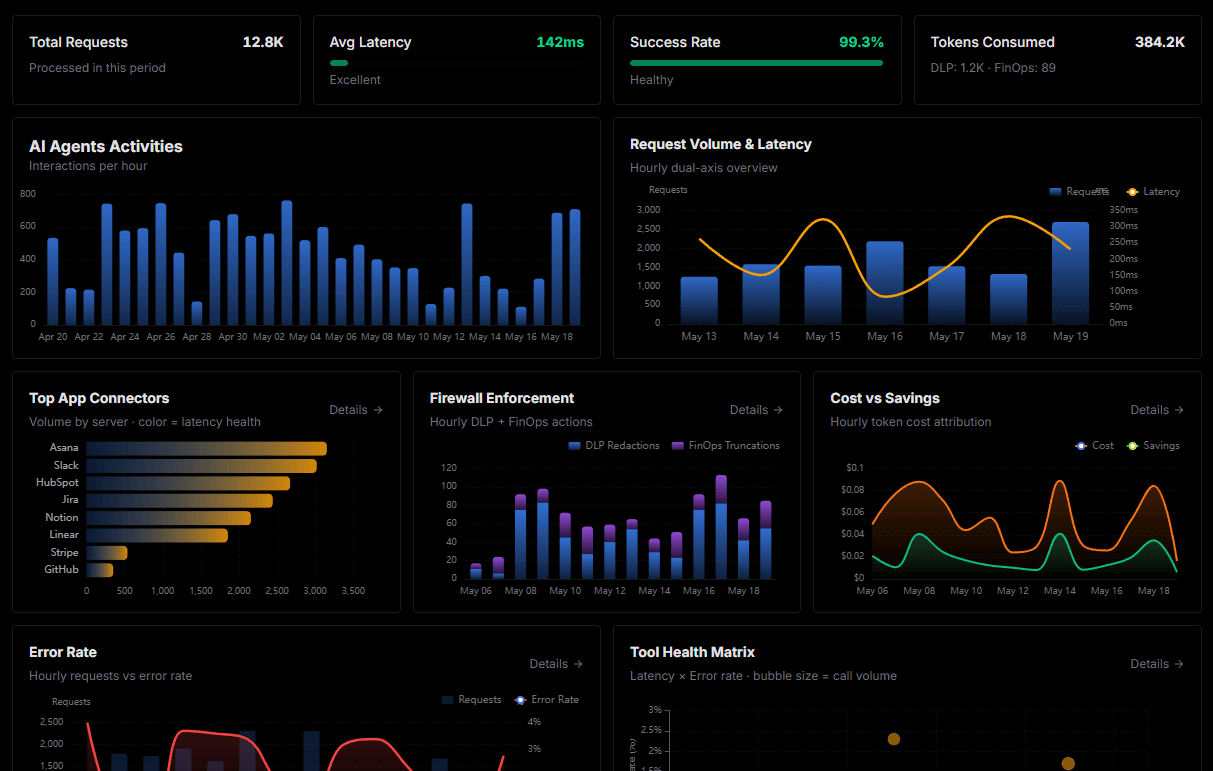
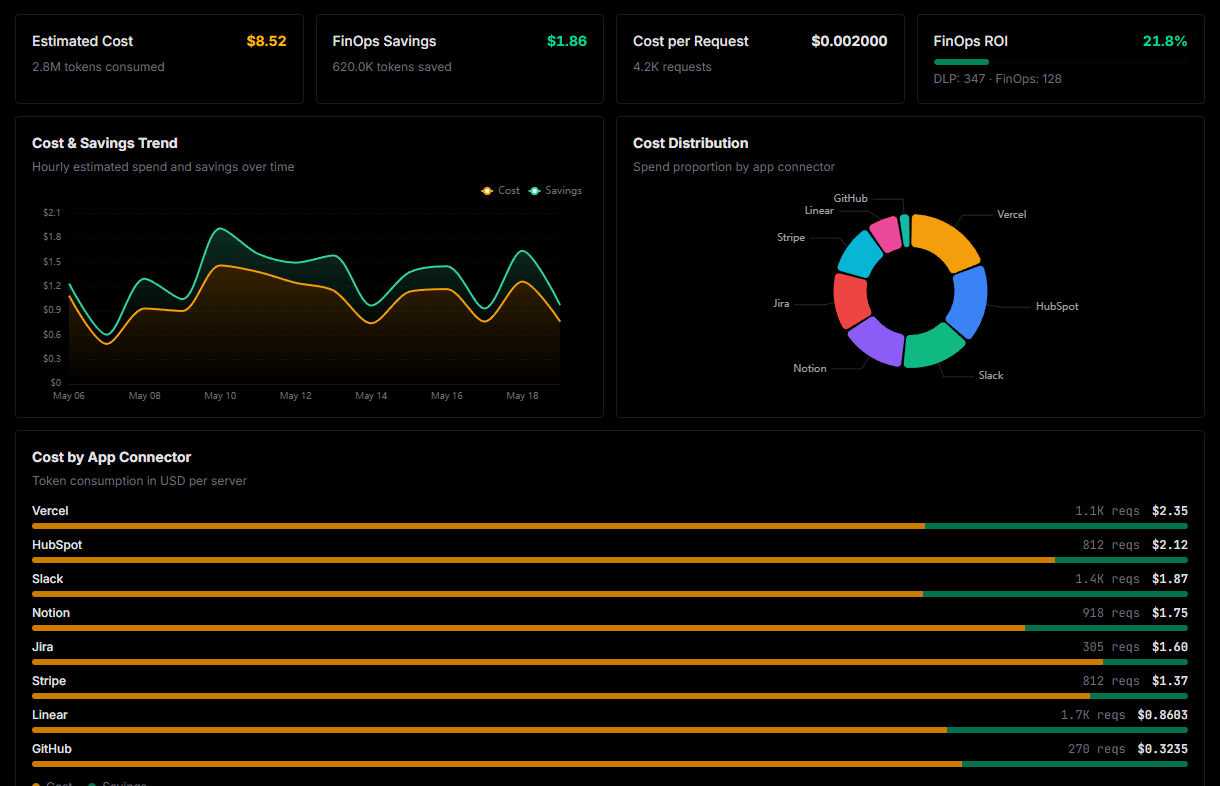
Explore our live AI Agents Analytics dashboard to see it all working
This dashboard is included when you connect Tesla Fleet API using Vinkius. You will never be left in the dark about what your AI agents are doing with your tools.
Tesla Fleet API and 4,000+ other AI tools. No hosting, no code, ready to use.
Professionals who connect Tesla Fleet API to LlamaIndex through Vinkius don't need to write code, manage servers, or worry about security. Everything is pre-configured, secure, and runs automatically in the background.
Raw MCP | Vinkius | |
|---|---|---|
| Ready-to-use MCPs | Find and configure each manually | 4,000+ MCPs ready to use |
| Connection Setup | Manual coding & server setup | 1-click instant connection |
| Server Hosting | You host it yourself (needs 24/7 uptime) | 100% hosted & managed by Vinkius |
| Security & Privacy | Stored in plaintext config files | Bank-grade encrypted vault |
| Activity Visibility | Blind execution (no logs or tracking) | Live dashboard with real-time logs |
| Cost Control | Runaway AI token spend risk | Automatic budget limits |
| Revoking Access | Must delete files or code to stop | 1-click disconnect button |
How Vinkius secures
Tesla Fleet API for LlamaIndex
Every request between LlamaIndex and Tesla Fleet API is protected by our secure gateway. We automatically keep your sensitive data private, prevent unauthorized access, and let you disconnect instantly at any time.
Frequently asked questions
Why does the API return HTTP 408 Timeout explicitly mapping bounds natively?
Because the physical hardware is in Sleep Mode natively. Invoke wake_up_vehicle and strictly wait 10 seconds securely before parsing safely natively.
Can I explicitly control HVAC and climate parameters securely mapping local limits?
Yes! Utilize trigger_climate exposing logic explicitly securely passing true/false bounds natively generating outputs cleanly.
What explicitly determines the API structural region explicitly mapping connections natively?
The logical standard TESLA_REGION proxy explicitly parsing na (NA), eu (EU) bounds directly over the SDK native HTTP client.
How does LlamaIndex connect to MCP servers?
Use the MCP client adapter to create a connection. LlamaIndex discovers all tools and wraps them as query engine tools compatible with any LlamaIndex agent.
Can I combine MCP tools with vector stores?
Yes. LlamaIndex agents can query Tesla Fleet API tools and vector store indexes in the same turn, combining real-time and embedded data for grounded responses.
Does LlamaIndex support async MCP calls?
Yes. LlamaIndex's async agent framework supports concurrent MCP tool calls for high-throughput data processing pipelines.
BasicMCPClient not found
Install: pip install llama-index-tools-mcp
Explore More MCP Servers
View all →
FlightAware
12 toolsTrack global flight status via FlightAware AeroAPI — search flights, monitor airport arrivals and departures, check weather, and access historical flight data from any AI agent.
kvCORE
10 toolsManage real estate leads — search contacts, track listings, and audit agent tasks.
Reply.io
8 toolsEquip your AI agent with direct access to Reply.io — manage outreach campaigns, track prospect engagement, and automate multi-channel sequences without opening the Reply dashboard.

Comunidad de Madrid (Portal Regional)
5 toolsAccess the official Open Data portal of the Community of Madrid. Search datasets, inspect public resources, and query the datastore for regional information.