Bring Web Crawling
to LlamaIndex
Create your Vinkius account to connect Web Scraper to LlamaIndex and start using all 5 AI tools in minutes. Fully managed, enterprise secure, and ready to use without writing a single line of code. No hosting, no server setup — just connect and start using.
Compatible with every major AI agent and IDE
 Gemini
Gemini
What is the Web Scraper MCP Server?
Connect the Web Scraper utility to any AI agent to give it direct access to the public internet. Instead of letting the AI hallucinate facts, allow it to read real-time articles, parse documentation, and fetch clean text from any URL you provide.
What you can do
- Reader View — Convert any cluttered webpage into pristine, readable Markdown by stripping out ads, navbars, and boilerplate using Mozilla Readability logic
- Site Crawling — Instruct the AI to crawl a starting URL (like a documentation hub or wiki) up to 10 pages deep automatically
- Batch Processing — Fetch up to 10 different URLs in parallel to compare articles or summarize multiple sources at once
- Metadata Extraction — Quickly pull SEO titles, descriptions, OG tags, canonical links, and all outbound hyperlinks without downloading the entire page body
How it works
- Subscribe to this server
- No API keys or authentication required
- Simply paste a link in your chat and tell your agent to 'read this URL' or 'crawl this documentation'
Who is this for?
- Developers — point the agent to a new library's API docs and have it write code using the absolute latest syntax
- Researchers — drop a handful of Wikipedia links and ask the AI to synthesize a comprehensive summary from the fetched data
- SEO Specialists — audit a webpage's metadata, extracted titles, and outbound link structure dynamically
Built-in capabilities (5)
All URLs are fetched in parallel. Maximum 10 URLs per batch. Fetch multiple web pages in parallel
Maximum 10 pages to keep response size manageable. Crawl a website starting from a URL
Returns: title, description, OG tags, lang, author, robots, canonical, link count. For the full page content, use the read tool instead. Extract structured metadata from a web page: title, description, OG tags, and more
Internal links share the same hostname as the source page. Extract all hyperlinks from a web page
Uses @mozilla/readability (Firefox Reader View) to extract the main article content, then converts to Markdown. Works best for articles, docs, blogs, and Wikipedia. Fetch any public web page and return its full content as clean Markdown
Why LlamaIndex?
LlamaIndex agents combine Web Scraper tool responses with indexed documents for comprehensive, grounded answers. Connect 5 tools through Vinkius and query live data alongside vector stores and SQL databases in a single turn. ideal for hybrid search, data enrichment, and analytical workflows.
- —
Data-first architecture: LlamaIndex agents combine Web Scraper tool responses with indexed documents for comprehensive, grounded answers
- —
Query pipeline framework lets you chain Web Scraper tool calls with transformations, filters, and re-rankers in a typed pipeline
- —
Multi-source reasoning: agents can query Web Scraper, a vector store, and a SQL database in a single turn and synthesize results
- —
Observability integrations show exactly what Web Scraper tools were called, what data was returned, and how it influenced the final answer
Web Scraper in LlamaIndex
Why run Web Scraper with Vinkius?
The Web Scraper connection runs on our fully managed, secure cloud infrastructure. We handle the hosting, maintenance, and security so you don't have to deal with servers or code. All 5 tools are ready to work instantly without any complex setup.
You stay in complete control of your data. Your AI only accesses the information you approve, keeping your sensitive passwords and private details completely safe. Plus, with automatic optimizations, your AI works faster and more efficiently.
* Every connection is hosted and maintained by Vinkius. We handle the security, updates, and infrastructure so you don't have to write code or manage servers. See our infrastructure
Over 4,000 integrations ready for AI agents
Explore a vast library of pre-built integrations, optimized and ready to deploy.
Connect securely in under 30 seconds
Generate tokens to authenticate and link external services in a single step.
Complete visibility into every agent action
Audit live requests, latency, success rates, and active security compliance policies.
Optimize spending and track token ROI
Analyze real-time token consumption and cost metrics detailed by connection.
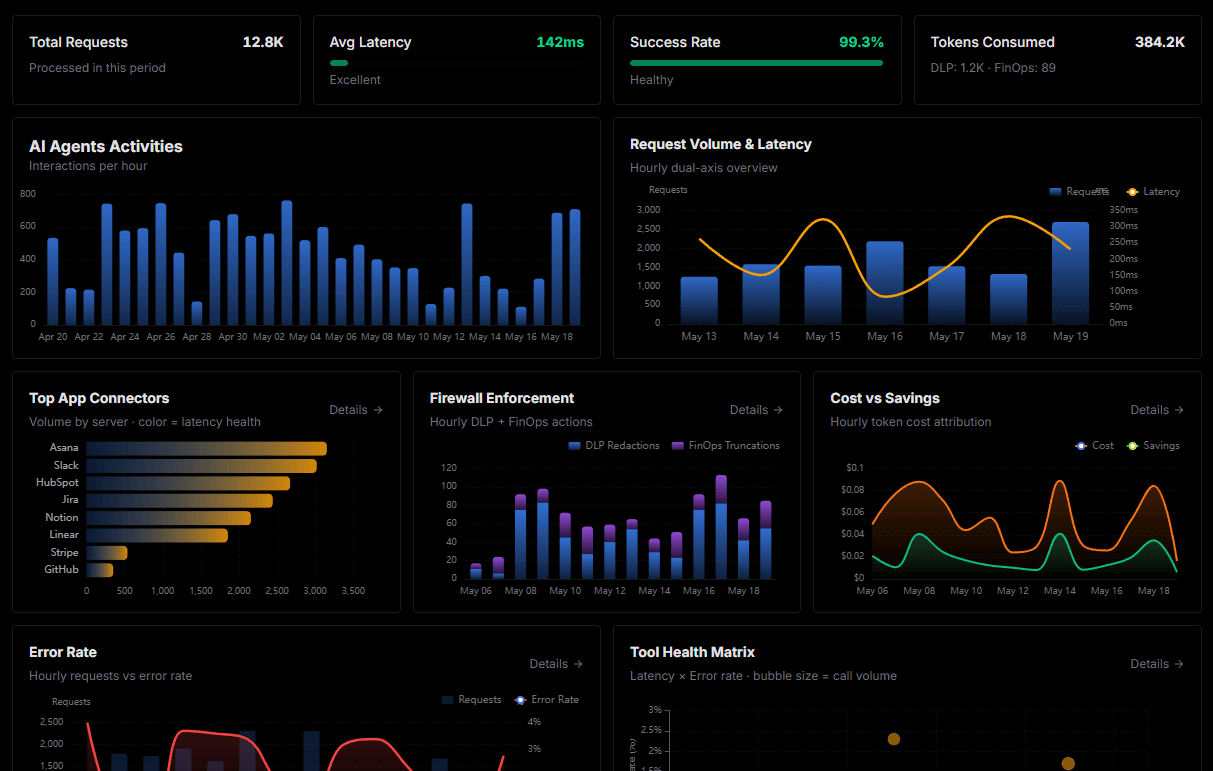
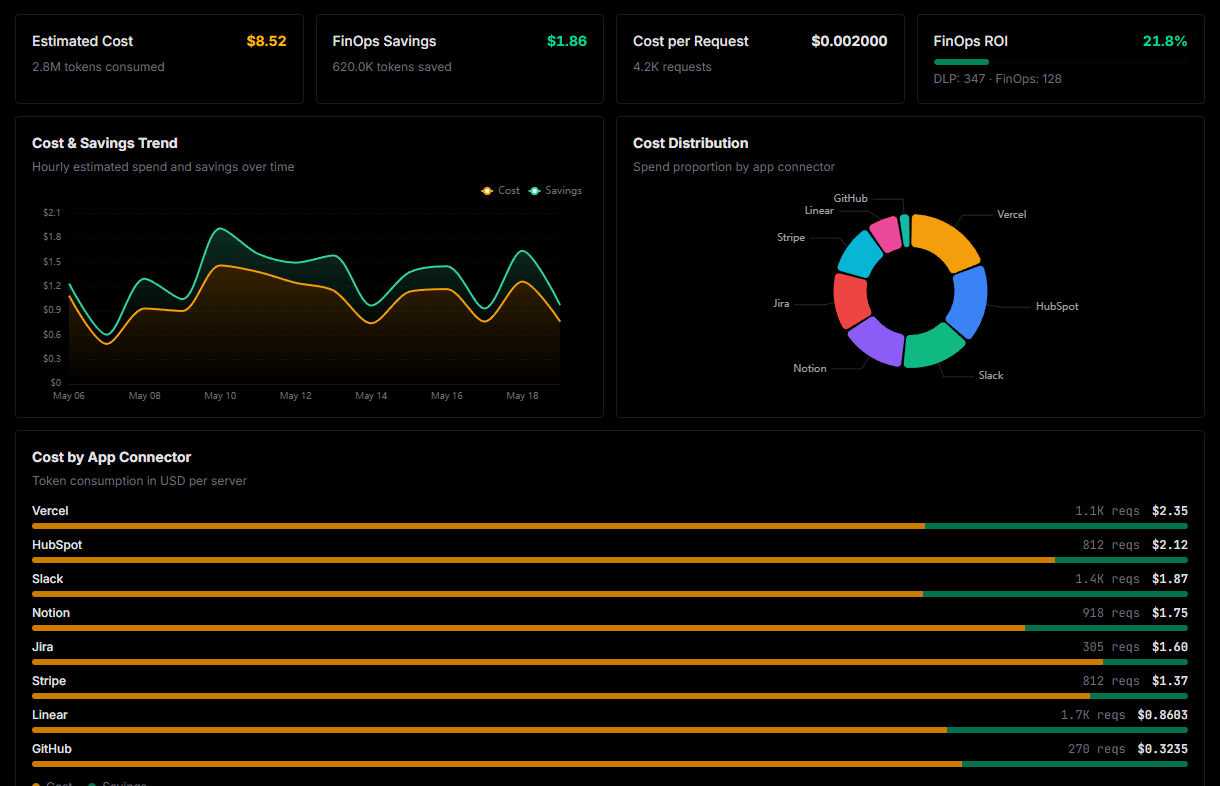
Explore our live AI Agents Analytics dashboard to see it all working
This dashboard is included when you connect Web Scraper using Vinkius. You will never be left in the dark about what your AI agents are doing with your tools.
Web Scraper and 4,000+ other AI tools. No hosting, no code, ready to use.
Professionals who connect Web Scraper to LlamaIndex through Vinkius don't need to write code, manage servers, or worry about security. Everything is pre-configured, secure, and runs automatically in the background.
Raw MCP | Vinkius | |
|---|---|---|
| Ready-to-use MCPs | Find and configure each manually | 4,000+ MCPs ready to use |
| Connection Setup | Manual coding & server setup | 1-click instant connection |
| Server Hosting | You host it yourself (needs 24/7 uptime) | 100% hosted & managed by Vinkius |
| Security & Privacy | Stored in plaintext config files | Bank-grade encrypted vault |
| Activity Visibility | Blind execution (no logs or tracking) | Live dashboard with real-time logs |
| Cost Control | Runaway AI token spend risk | Automatic budget limits |
| Revoking Access | Must delete files or code to stop | 1-click disconnect button |
How Vinkius secures
Web Scraper for LlamaIndex
Every request between LlamaIndex and Web Scraper is protected by our secure gateway. We automatically keep your sensitive data private, prevent unauthorized access, and let you disconnect instantly at any time.
Frequently asked questions
Can it read documentation sites that are split into multiple pages?
Yes! You can use the crawl tool. For example: 'Crawl the getting started guide at https://example.com/docs'. The agent will fetch the starting page and automatically follow inner links to gather up to 10 pages of context.
How does it handle ads and cluttered websites?
The read tool uses the same underlying technology as Firefox's 'Reader View' (@mozilla/readability). It intelligently strips out standard website boilerplate—like navbars, sidebars, footers, and ads—leaving only the title and the clean main article text converted to Markdown.
Is there a limit on how many URLs I can batch process?
Yes, to ensure conversational AI latency remains reasonable, the batch_read tool accepts a maximum of 10 URLs in a single request. All 10 URLs are fetched simultaneously in parallel for maximum speed.
How does LlamaIndex connect to MCP servers?
Use the MCP client adapter to create a connection. LlamaIndex discovers all tools and wraps them as query engine tools compatible with any LlamaIndex agent.
Can I combine MCP tools with vector stores?
Yes. LlamaIndex agents can query Web Scraper tools and vector store indexes in the same turn, combining real-time and embedded data for grounded responses.
Does LlamaIndex support async MCP calls?
Yes. LlamaIndex's async agent framework supports concurrent MCP tool calls for high-throughput data processing pipelines.
BasicMCPClient not found
Install: pip install llama-index-tools-mcp
Explore More MCP Servers
View all →
Ontraport
10 toolsManage marketing and sales via Ontraport — list contacts, track campaigns, and monitor transactions directly from any AI agent.
Billit
9 toolsManage your e-invoicing via Billit — list invoices, clients, and expenses directly from any AI agent.

Lemon Squeezy
12 toolsSell software, subscriptions, and digital products globally with built-in tax compliance, billing, and licensing as your merchant of record.

BlueSnap
10 toolsProcess and manage payments via BlueSnap — list transactions, subscriptions, and vaulted shoppers directly from any AI agent.