Bring Llm Gateway
to AutoGen
Create your Vinkius account to connect LiteLLM (LLM Proxy & Spend Tracking) to AutoGen and start using all 10 AI tools in minutes. Fully managed, enterprise secure, and ready to use without writing a single line of code. No hosting, no server setup — just connect and start using.
Compatible with every major AI agent and IDE
 Gemini
GeminiWhat is the LiteLLM (LLM Proxy & Spend Tracking) MCP Server?
Connect your LiteLLM Proxy instance to any AI agent and take full control of your LLM infrastructure, load balancing, and spend management through natural conversation.
What you can do
- Key Orchestration — Generate and manage proxy API keys to isolate distinct microservices or teams, including precise budget and rate limit constraints directly from your agent
- Model Routing Intelligence — Get detailed info on fallback paths (e.g., OpenAI -> Anthropic -> Groq) and verify exact routing endpoints assigned to your models
- Real-time Spend Audit — Track total USD consumed by specific end-users or teams and monitor budget ceilings to ensure cost-effective AI deployments
- Dynamic Model Control — Inject fresh routing endpoints (e.g., new AWS Bedrock or Azure OpenAI deployments) into your proxy runtime with zero downtime
- Team & Organizational Isolation — Create and manage team profiles to track exact cost limits and operational boundaries per organizational division
- Infrastructure Security — Instantly vaporize malicious or leaked keys and remove broken LLM deployments to prevent downstream 500 errors dynamically
How it works
- Subscribe to this server
- Enter your LiteLLM API URL and Master Key
- Start managing your LLM gateway from Claude, Cursor, or any MCP-compatible client
Who is this for?
- Platform Engineers — manage global LLM gateway configurations and audit model fallback paths through natural conversation
- AI Ops Teams — monitor real-time AI spending and adjust team budgets across multiple LLM providers
- Backend Developers — generate sub-keys for new microservices and verify model routing availability without leaving your IDE
Built-in capabilities (10)
Inject completely fresh routing endpoints (ex: new Bedrock Llama 4 endpoints)
Generate pristine organizational isolation tracking exact cost limits per division
Insert specific End-User identities bridging Vinkius with Proxy logs
Delete an existing LLM proxy key entirely
Delete explicitly routed LLM deployments preventing 500s dynamically
Generate a new proxy API key isolating distinct microservices or teams
Get configuration and budget bounds for a specific LiteLLM API Key
Get array endpoints tracing exact Fallback paths like OpenAI -> Anthropic
Get internal logic bounds matching multiple routing users via Team UUID
Return precise End-User abstractions tracking total USD consumed natively
Why AutoGen?
AutoGen enables multi-agent conversations where agents negotiate, delegate, and collaboratively use LiteLLM (LLM Proxy & Spend Tracking) tools. Connect 10 tools through Vinkius and assign role-based access. a data analyst queries while a reviewer validates, with optional human-in-the-loop approval for sensitive operations.
- —
Multi-agent conversations: multiple AutoGen agents discuss, delegate, and collaboratively use LiteLLM (LLM Proxy & Spend Tracking) tools to solve complex tasks
- —
Role-based architecture lets you assign LiteLLM (LLM Proxy & Spend Tracking) tool access to specific agents. a data analyst queries while a reviewer validates
- —
Human-in-the-loop support: agents can pause for human approval before executing sensitive LiteLLM (LLM Proxy & Spend Tracking) tool calls
- —
Code execution sandbox: AutoGen agents can write and run code that processes LiteLLM (LLM Proxy & Spend Tracking) tool responses in an isolated environment
LiteLLM (LLM Proxy & Spend Tracking) in AutoGen
Why run LiteLLM (LLM Proxy & Spend Tracking) with Vinkius?
The LiteLLM (LLM Proxy & Spend Tracking) connection runs on our fully managed, secure cloud infrastructure. We handle the hosting, maintenance, and security so you don't have to deal with servers or code. All 10 tools are ready to work instantly without any complex setup.
You stay in complete control of your data. Your AI only accesses the information you approve, keeping your sensitive passwords and private details completely safe. Plus, with automatic optimizations, your AI works faster and more efficiently.
* Every connection is hosted and maintained by Vinkius. We handle the security, updates, and infrastructure so you don't have to write code or manage servers. See our infrastructure
Over 4,000 integrations ready for AI agents
Explore a vast library of pre-built integrations, optimized and ready to deploy.
Connect securely in under 30 seconds
Generate tokens to authenticate and link external services in a single step.
Complete visibility into every agent action
Audit live requests, latency, success rates, and active security compliance policies.
Optimize spending and track token ROI
Analyze real-time token consumption and cost metrics detailed by connection.
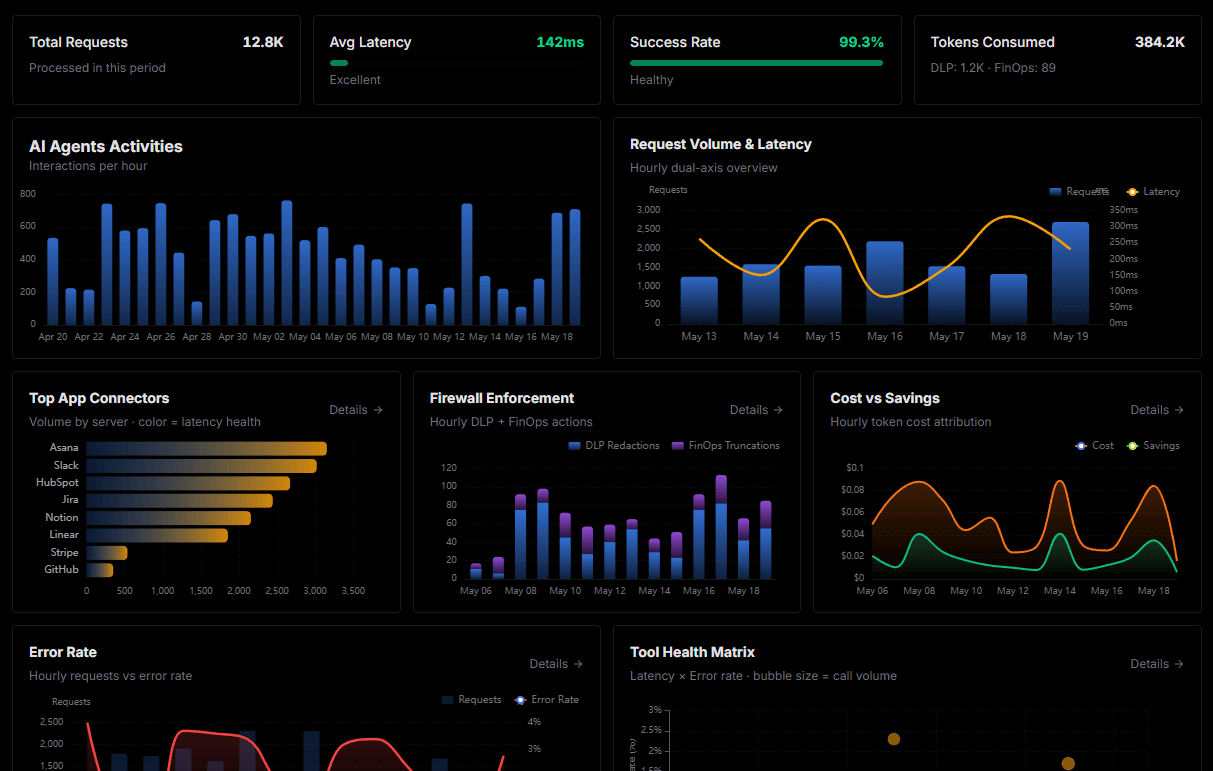
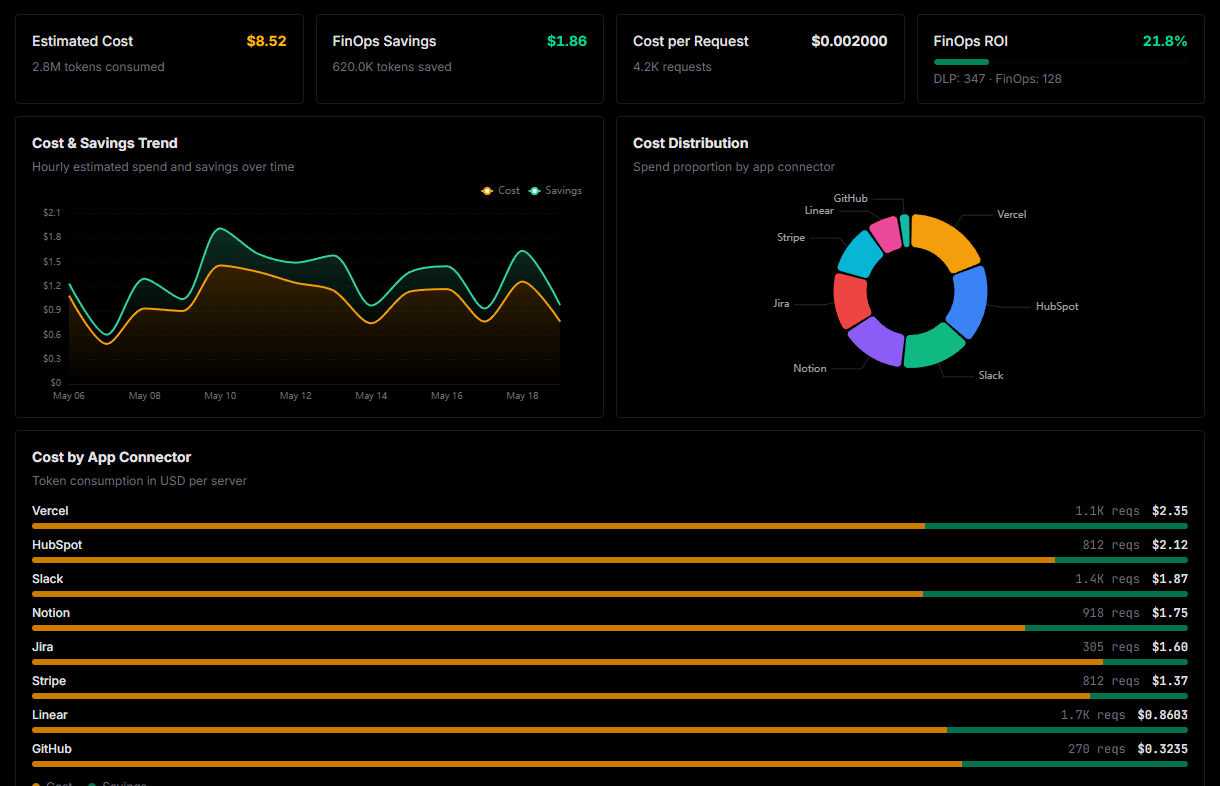
Explore our live AI Agents Analytics dashboard to see it all working
This dashboard is included when you connect LiteLLM (LLM Proxy & Spend Tracking) using Vinkius. You will never be left in the dark about what your AI agents are doing with your tools.
LiteLLM (LLM Proxy & Spend Tracking) and 4,000+ other AI tools. No hosting, no code, ready to use.
Professionals who connect LiteLLM (LLM Proxy & Spend Tracking) to AutoGen through Vinkius don't need to write code, manage servers, or worry about security. Everything is pre-configured, secure, and runs automatically in the background.
Raw MCP | Vinkius | |
|---|---|---|
| Ready-to-use MCPs | Find and configure each manually | 4,000+ MCPs ready to use |
| Connection Setup | Manual coding & server setup | 1-click instant connection |
| Server Hosting | You host it yourself (needs 24/7 uptime) | 100% hosted & managed by Vinkius |
| Security & Privacy | Stored in plaintext config files | Bank-grade encrypted vault |
| Activity Visibility | Blind execution (no logs or tracking) | Live dashboard with real-time logs |
| Cost Control | Runaway AI token spend risk | Automatic budget limits |
| Revoking Access | Must delete files or code to stop | 1-click disconnect button |
How Vinkius secures
LiteLLM (LLM Proxy & Spend Tracking) for AutoGen
Every request between AutoGen and LiteLLM (LLM Proxy & Spend Tracking) is protected by our secure gateway. We automatically keep your sensitive data private, prevent unauthorized access, and let you disconnect instantly at any time.
Frequently asked questions
Can I check the budget and rate limits for a specific proxy key?
Yes. Use the get_key_info tool with the specific Key ID. Your agent will retrieve the exact rate limits, budget constraints, and current RPM usage associated with that token.
How do I see the model fallback paths configured in my proxy?
The get_model_info tool allows your agent to extract the global model directory. You'll see the exact fallback chains (e.g., if OpenAI fails, use Anthropic) and the physical endpoints assigned to each model name.
Can my agent create a new team to track specific division costs?
Absolutely. Use the create_team tool and provide a JSON payload defining the team name and optional budget limits. Your agent will provision the new team identity in LiteLLM, allowing for precise organizational cost tracking.
How does AutoGen connect to MCP servers?
Create an MCP tool adapter and assign it to one or more agents in the group chat. AutoGen agents can then call LiteLLM (LLM Proxy & Spend Tracking) tools during their conversation turns.
Can different agents have different MCP tool access?
Yes. AutoGen's role-based architecture lets you assign specific MCP tools to specific agents, so a querying agent has different capabilities than a reviewing agent.
Does AutoGen support human approval for tool calls?
Yes. Configure human-in-the-loop mode so agents pause and request approval before executing sensitive MCP tool calls.
McpWorkbench not found
Install: pip install "autogen-ext[mcp]"
Explore More MCP Servers
View all →
Keywords AI
11 toolsMonitor and optimize your LLM API usage with a unified gateway that tracks costs, latency, and model performance across providers.

Weaviate
7 toolsSearch and manage vector data on Weaviate — the AI-native database for building production-grade AI applications.

U.S. EIA Energy Data
10 toolsEquip your AI agent to access official U.S. energy statistics, track electricity generation, and monitor fuel prices via the EIA API.

Wikidata
8 toolsAccess the world's largest open knowledge graph—query entities via SPARQL, perform vector searches, and manage structured data directly from your AI agent.