Bring Serverless
to CrewAI
Create your Vinkius account to connect Cloudflare to CrewAI and start using all 25 AI tools in minutes. Fully managed, enterprise secure, and ready to use without writing a single line of code. No hosting, no server setup — just connect and start using.
Compatible with every major AI agent and IDE
 Gemini
Gemini
What is the Cloudflare MCP Server?
What you can do
Connect AI agents to Cloudflare's platform for comprehensive edge infrastructure management:
- Manage Workers — list, inspect, delete serverless functions across your account
- Control deployments — version history, immediate/gradual rollouts, rollback capabilities
- Manage secrets — create, list, and delete encrypted environment secrets securely
- Configure routes — URL patterns that trigger Workers at specific paths or domains
- Query KV storage — read/write key-value pairs from Workers KV namespaces
- Execute D1 queries — run SQL queries against Cloudflare's serverless SQLite databases
- Inspect R2 buckets — list and manage object storage buckets
- Monitor analytics — zone traffic, Worker invocations, CPU usage, and error rates
- Tail Worker logs — create real-time logging sessions for debugging in production
- Purge CDN cache — clear cached content to serve fresh origin data
How it works
- Generate a Cloudflare API token with Workers, KV, D1, R2, and Analytics permissions
- Find your Account ID from the Cloudflare dashboard
- Ask your AI agent to deploy Workers, manage secrets, query databases, or monitor analytics
- Natural language commands replace manual Wrangler CLI or dashboard operations
Who is this for?
Essential for edge application developers, serverless architects, DevOps engineers, full-stack developers, and platform teams using Cloudflare's ecosystem. Let AI agents handle continuous Worker deployments, secret rotation, KV data management, D1 database queries, production debugging, and infrastructure monitoring. Perfect for teams running production workloads on Cloudflare who want to eliminate manual Wrangler steps, accelerate deployment cycles, and enable AI-driven edge operations.
Built-in capabilities (25)
Strategy can be immediate (100% traffic immediately) or gradual (percentage-based rollout). Requires script name, version ID, and deployment strategy. Use this to roll out new features, rollback to previous versions, or perform canary deployments. Deploy a specific Worker version to traffic
Secrets are encrypted at rest and injected at runtime. Requires script name, secret name, and secret value. Common use: API keys, database passwords, OAuth tokens. The secret becomes available via env.VARIABLE_NAME in your Worker code. Create or update a secret for a Cloudflare Worker
log() output and exceptions. Returns a tail ID and WebSocket URL for streaming logs. Use this for debugging Workers in production or monitoring error output. Create a tail logging session for a Cloudflare Worker
Requires zone ID, URL pattern (e.g., "example.com/api/*"), and script name. Use this to expose your Worker at specific URL paths or domains. Create a new route pattern for a Cloudflare Worker
Use this to clean up unused secrets or rotate credentials. Requires script name and secret name. After deletion, the Worker will no longer have access to the secret value. Delete a secret from a Cloudflare Worker
Requires script name and tail ID. Use this to clean up unused tail sessions when debugging is complete. Delete a tail logging session for a Cloudflare Worker
This action cannot be undone. Requires the script name. Confirm with the user before proceeding. Delete a Cloudflare Worker script and all its associated resources
Use this to stop serving a Worker at specific URLs. Requires zone ID and route ID. Delete a route pattern from a Cloudflare Worker
Returns the raw value as JSON. Use this to read configuration values, cached responses, or user data stored in KV. Get the value of a specific key in a KV namespace
Requires the script name from list_workers results. Use this to review Worker configuration before making updates or debugging. Get detailed information about a specific Cloudflare Worker
Returns data for recent invocations. Use this to monitor Worker performance, identify errors, or track usage trends. Get analytics data for a specific Cloudflare Worker
Requires script name and version ID from list_worker_versions results. Use this to audit version contents or prepare for rollback deployment. Get detailed information about a specific Worker version
Returns aggregated data for the last 24 hours. Use this to monitor traffic patterns, identify spikes, or measure CDN performance. Get analytics data for a specific Cloudflare zone
Returns database IDs, names, creation dates, and file sizes. Use this to identify available databases before querying. List all D1 databases in your Cloudflare account
Returns deployment IDs, version IDs, strategies (immediate, gradual), creation dates, and traffic percentages. Use this to review current deployment state, monitor gradual rollouts, or identify which version is live. List all deployments for a specific Cloudflare Worker
Returns key names, expiration metadata, and sizes. Use this to audit stored data or find specific keys before reading values. List all keys in a specific KV namespace
KV namespaces are key-value stores for Workers. Returns namespace IDs, titles, and creation dates. Use this to identify which namespaces exist before reading/writing data. List all KV namespaces in your Cloudflare account
Returns bucket names, creation dates, and storage locations. Use this to identify available storage buckets before managing objects. List all R2 storage buckets in your Cloudflare account
Returns secret names and types (secret_text, secret_key). Secret values are never returned for security. Use this to audit which secrets are configured before adding new ones or cleaning up unused secrets. List all secrets for a specific Cloudflare Worker
Returns route patterns, associated script names, and zone IDs. Use this to understand which URLs invoke your Worker before adding or removing routes. List all route patterns associated with a Cloudflare Worker
Each version represents a deployed code snapshot with unique ID, creation date, and metadata. Returns version IDs, timestamps, and author information. Use this to review deployment history, rollback to previous versions, or audit code changes. List all versions of a specific Cloudflare Worker
Returns script names, creation dates, modification dates, and deployment status. Use this as the first step to identify which Workers exist before managing versions, deployments, or secrets. List all Cloudflare Workers scripts in your account
Returns zone IDs, domain names, status, plan, and name servers. Use this to identify zone IDs needed for Worker routes, DNS management, or cache operations. List all DNS zones in your Cloudflare account
Use this after deploying content changes or updating static assets. Requires zone ID. Purge all cached content for a specific zone
Supports SELECT, INSERT, UPDATE, DELETE operations. Returns query results as JSON. Use this for data analysis, migrations, or ad-hoc queries. Requires database ID and SQL query string. Execute a SQL query against a D1 database
Why CrewAI?
When paired with CrewAI, Cloudflare becomes a first-class tool in your multi-agent workflows. Each agent in the crew can call Cloudflare tools autonomously, one agent queries data, another analyzes results, a third compiles reports, all orchestrated through Vinkius with zero configuration overhead.
- —
Multi-agent collaboration lets you decompose complex workflows into specialized roles, one agent researches, another analyzes, a third generates reports, each with access to MCP tools
- —
CrewAI's native MCP integration requires zero adapter code: pass Vinkius Edge URL directly in the
mcpsparameter and agents auto-discover every available tool at runtime - —
Built-in task delegation and shared memory mean agents can pass context between steps without manual state management, enabling multi-hop reasoning across tool calls
- —
Sequential and hierarchical crew patterns map naturally to real-world workflows: enumerate subdomains → analyze DNS history → check WHOIS records → compile findings into actionable reports
Cloudflare in CrewAI
Why run Cloudflare with Vinkius?
The Cloudflare connection runs on our fully managed, secure cloud infrastructure. We handle the hosting, maintenance, and security so you don't have to deal with servers or code. All 25 tools are ready to work instantly without any complex setup.
You stay in complete control of your data. Your AI only accesses the information you approve, keeping your sensitive passwords and private details completely safe. Plus, with automatic optimizations, your AI works faster and more efficiently.
* Every connection is hosted and maintained by Vinkius. We handle the security, updates, and infrastructure so you don't have to write code or manage servers. See our infrastructure
Over 4,000 integrations ready for AI agents
Explore a vast library of pre-built integrations, optimized and ready to deploy.
Connect securely in under 30 seconds
Generate tokens to authenticate and link external services in a single step.
Complete visibility into every agent action
Audit live requests, latency, success rates, and active security compliance policies.
Optimize spending and track token ROI
Analyze real-time token consumption and cost metrics detailed by connection.
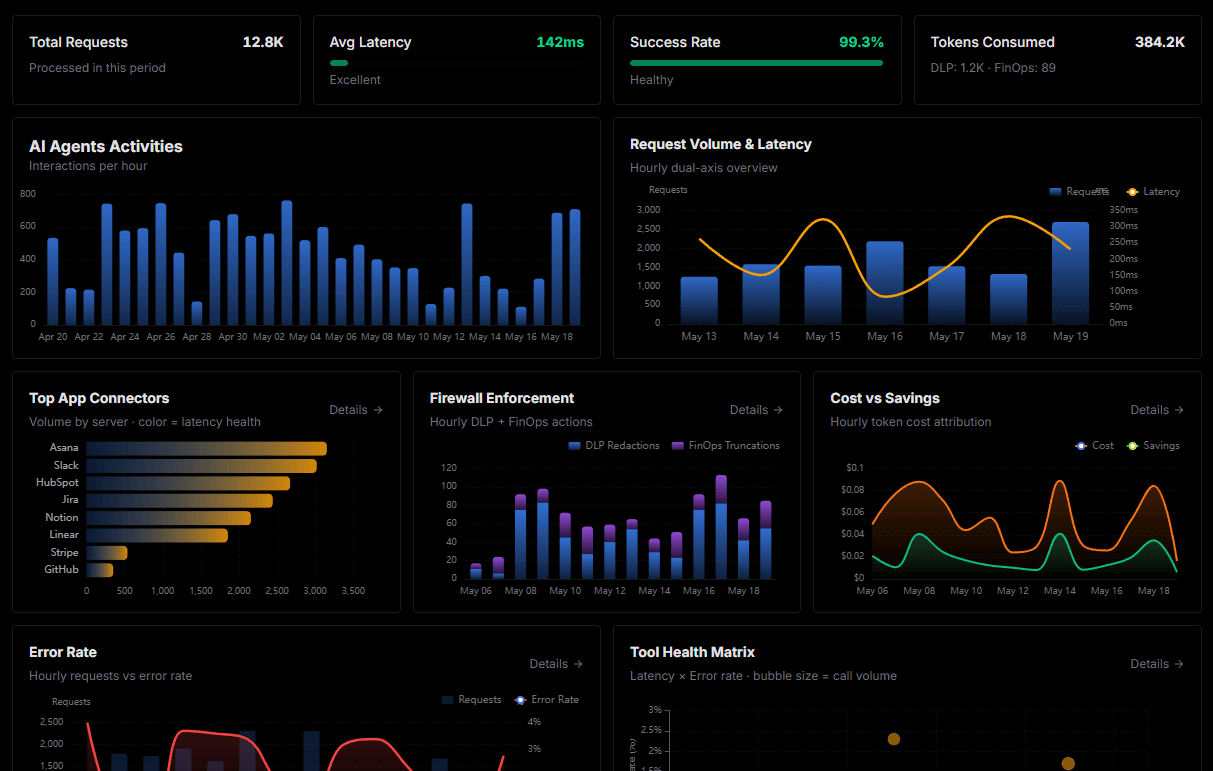
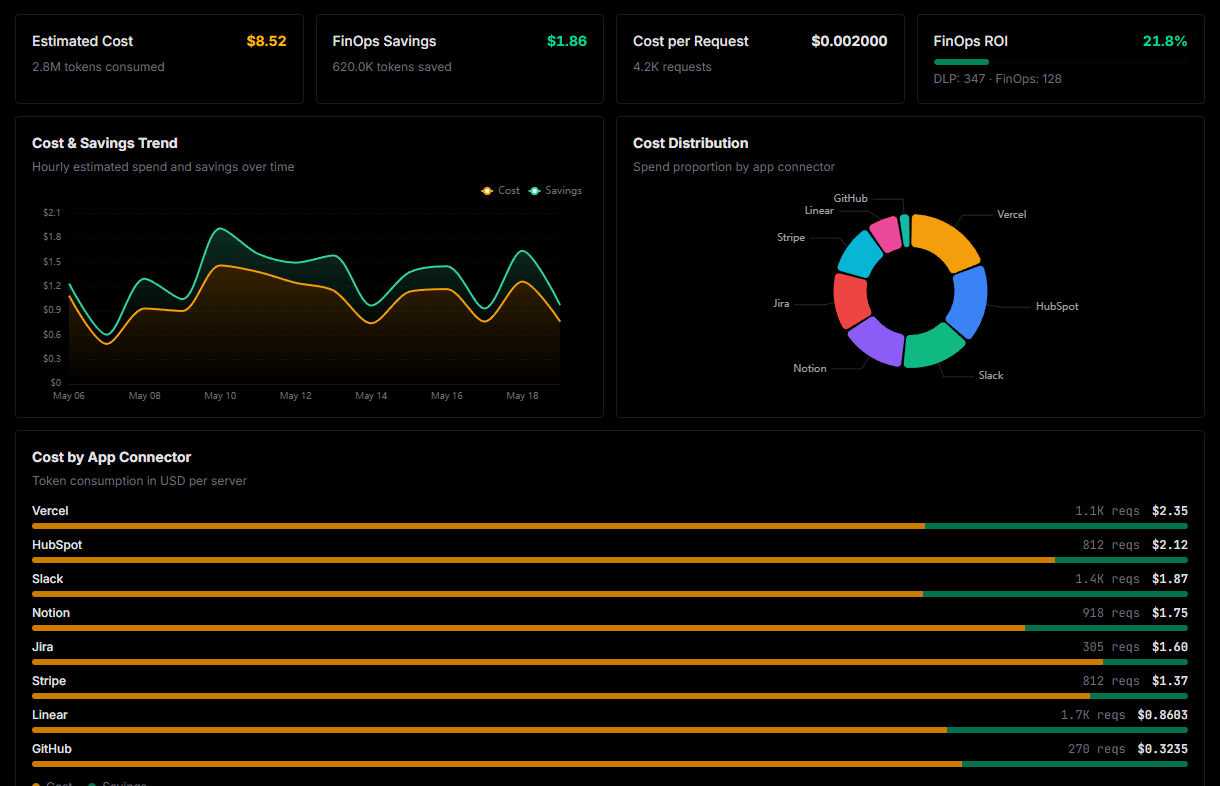
Explore our live AI Agents Analytics dashboard to see it all working
This dashboard is included when you connect Cloudflare using Vinkius. You will never be left in the dark about what your AI agents are doing with your tools.
Cloudflare and 4,000+ other AI tools. No hosting, no code, ready to use.
Professionals who connect Cloudflare to CrewAI through Vinkius don't need to write code, manage servers, or worry about security. Everything is pre-configured, secure, and runs automatically in the background.
Raw MCP | Vinkius | |
|---|---|---|
| Ready-to-use MCPs | Find and configure each manually | 4,000+ MCPs ready to use |
| Connection Setup | Manual coding & server setup | 1-click instant connection |
| Server Hosting | You host it yourself (needs 24/7 uptime) | 100% hosted & managed by Vinkius |
| Security & Privacy | Stored in plaintext config files | Bank-grade encrypted vault |
| Activity Visibility | Blind execution (no logs or tracking) | Live dashboard with real-time logs |
| Cost Control | Runaway AI token spend risk | Automatic budget limits |
| Revoking Access | Must delete files or code to stop | 1-click disconnect button |
How Vinkius secures
Cloudflare for CrewAI
Every request between CrewAI and Cloudflare is protected by our secure gateway. We automatically keep your sensitive data private, prevent unauthorized access, and let you disconnect instantly at any time.
Frequently asked questions
Can I deploy new Worker scripts directly through the AI agent?
Yes! You can orchestrate deployments natively mapping source code variables seamlessly without touching Wrangler.
Does it interact with specific D1 Serverless SQL definitions?
Absolutely. Ask your agent to parse complex D1 databases and query tables instantly utilizing precise analytical calls.
How are environment variables and secrets handled?
All add_secret queries execute symmetrically securely masking output variables while committing seamlessly inside Cloudflare matrices.
How does CrewAI discover and connect to MCP tools?
CrewAI connects to MCP servers lazily. when the crew starts, each agent resolves its MCP URLs and fetches the tool catalog via the standard tools/list method. This means tools are always fresh and reflect the server's current capabilities. No tool schemas need to be hardcoded.
Can different agents in the same crew use different MCP servers?
Yes. Each agent has its own mcps list, so you can assign specific servers to specific roles. For example, a reconnaissance agent might use a domain intelligence server while an analysis agent uses a vulnerability database server.
What happens when an MCP tool call fails during a crew run?
CrewAI wraps tool failures as context for the agent. The LLM receives the error message and can decide to retry with different parameters, fall back to a different tool, or mark the task as partially complete. This resilience is critical for production workflows.
Can CrewAI agents call multiple MCP tools in parallel?
CrewAI agents execute tool calls sequentially within a single reasoning step. However, you can run multiple agents in parallel using process=Process.parallel, each calling different MCP tools concurrently. This is ideal for workflows where separate data sources need to be queried simultaneously.
Can I run CrewAI crews on a schedule (cron)?
Yes. CrewAI crews are standard Python scripts, so you can invoke them via cron, Airflow, Celery, or any task scheduler. The crew.kickoff() method runs synchronously by default, making it straightforward to integrate into existing pipelines.
MCP tools not discovered
Ensure the Edge URL is correct. CrewAI connects lazily when the crew starts. check console output.
Agent not using tools
Make the task description specific. Instead of "do something", say "Use the available tools to list contacts".
Timeout errors
CrewAI has a 10s connection timeout by default. Ensure your network can reach the Edge URL.
Rate limiting or 429 errors
Vinkius enforces per-token rate limits. Check your subscription tier and request quota in the dashboard. Upgrade if you need higher throughput.
Explore More MCP Servers
View all →
MeiQia
10 toolsLeading live chat and customer CRM platform — manage conversations, messages, and customers via AI.

Chuangkit / 创客贴
8 toolsLeading graphic design platform in China — manage templates, materials, and designs via AI.

DataDive
10 toolsEquip your AI agent to retrieve Amazon seller insights, keyword rankings, and niche analytics directly via the DataDive API.

DealHub CPQ
10 toolsManage CPQ and sales via DealHub — create quotes, track opportunity stages, manage users, and sync CRM data directly from any AI agent.