Bring Model Discovery
to Mastra AI
Create your Vinkius account to connect NVIDIA API Catalog to Mastra AI and start using all 8 AI tools in minutes. Fully managed, enterprise secure, and ready to use without writing a single line of code. No hosting, no server setup — just connect and start using.
Compatible with every major AI agent and IDE
 Gemini
Gemini
What is the NVIDIA API Catalog MCP Server?
What you can do
Trigger massive inference executions navigating safely over natively hosted logic endpoints using the explicit API Catalog:
- Discover Active Cloud LLMs natively listing every explicitly hosted model configuration safely mapped
- Route Chat Completions pulling explicit answers evaluating safely unstructured conversational bounds dynamically
- Extract Native Embeddings passing direct text evaluations extracting numerical arrays gracefully
- Evaluate Multimodal limits assigning native Vision tasks routing natively strictly matrix limits
- Execute Text Summarization compressing explicit bounds generating specific arrays cleanly routing effectively
How it works
- Declare Logic Tokens, explicitly combining the
NVIDIA_API_KEYconfiguration natively over the SDK bounds proxy implicitly - Pass Strict Logic Inference, requesting native models securely bypassing manual SDK mapping configurations resolving completely
- Map and execute hardware limits inherently parsing directly standard structured completions securely
Who is this for?
Explicitly targeted evaluating limits specifically for AI Engineers, Generative Integrators, and Developers parsing direct responses over public NVIDIA compute matrices.
Built-in capabilities (8)
Trigger direct NLP inference matrices directly evaluating queries over hosted LLMs
Poll safely dynamic credit and explicit constraint execution limits bounding inference execution
Pass parameters safely mapping explicit unstructured vectors directly using specific Embedding arrays
Ping explicitly the core hosted NVIDIA matrix tracing inference endpoints evaluating latencies securely
Dumps the strict array specifying explicit LLM matrix paths accessible securely natively
Evaluate explicit matrices tracking fine-tuned overrides isolating logical constraints dynamically
Standard natively configured logical execution executing predefined abstract compression matrices smoothly
g. Llama-Vision natively). Invoke strictly multimodal abilities capturing diagnostic constraints returning inference on graphical data
Why Mastra AI?
Mastra's agent abstraction provides a clean separation between LLM logic and NVIDIA API Catalog tool infrastructure. Connect 8 tools through Vinkius and use Mastra's built-in workflow engine to chain tool calls with conditional logic, retries, and parallel execution. deployable to any Node.js host in one command.
- —
Mastra's agent abstraction provides a clean separation between LLM logic and tool infrastructure. add NVIDIA API Catalog without touching business code
- —
Built-in workflow engine chains MCP tool calls with conditional logic, retries, and parallel execution for complex automation
- —
TypeScript-native: full type inference for every NVIDIA API Catalog tool response with IDE autocomplete and compile-time checks
- —
One-command deployment to any Node.js host. Vercel, Railway, Fly.io, or your own infrastructure
NVIDIA API Catalog in Mastra AI
Why run NVIDIA API Catalog with Vinkius?
The NVIDIA API Catalog connection runs on our fully managed, secure cloud infrastructure. We handle the hosting, maintenance, and security so you don't have to deal with servers or code. All 8 tools are ready to work instantly without any complex setup.
You stay in complete control of your data. Your AI only accesses the information you approve, keeping your sensitive passwords and private details completely safe. Plus, with automatic optimizations, your AI works faster and more efficiently.
* Every connection is hosted and maintained by Vinkius. We handle the security, updates, and infrastructure so you don't have to write code or manage servers. See our infrastructure
Over 4,000 integrations ready for AI agents
Explore a vast library of pre-built integrations, optimized and ready to deploy.
Connect securely in under 30 seconds
Generate tokens to authenticate and link external services in a single step.
Complete visibility into every agent action
Audit live requests, latency, success rates, and active security compliance policies.
Optimize spending and track token ROI
Analyze real-time token consumption and cost metrics detailed by connection.
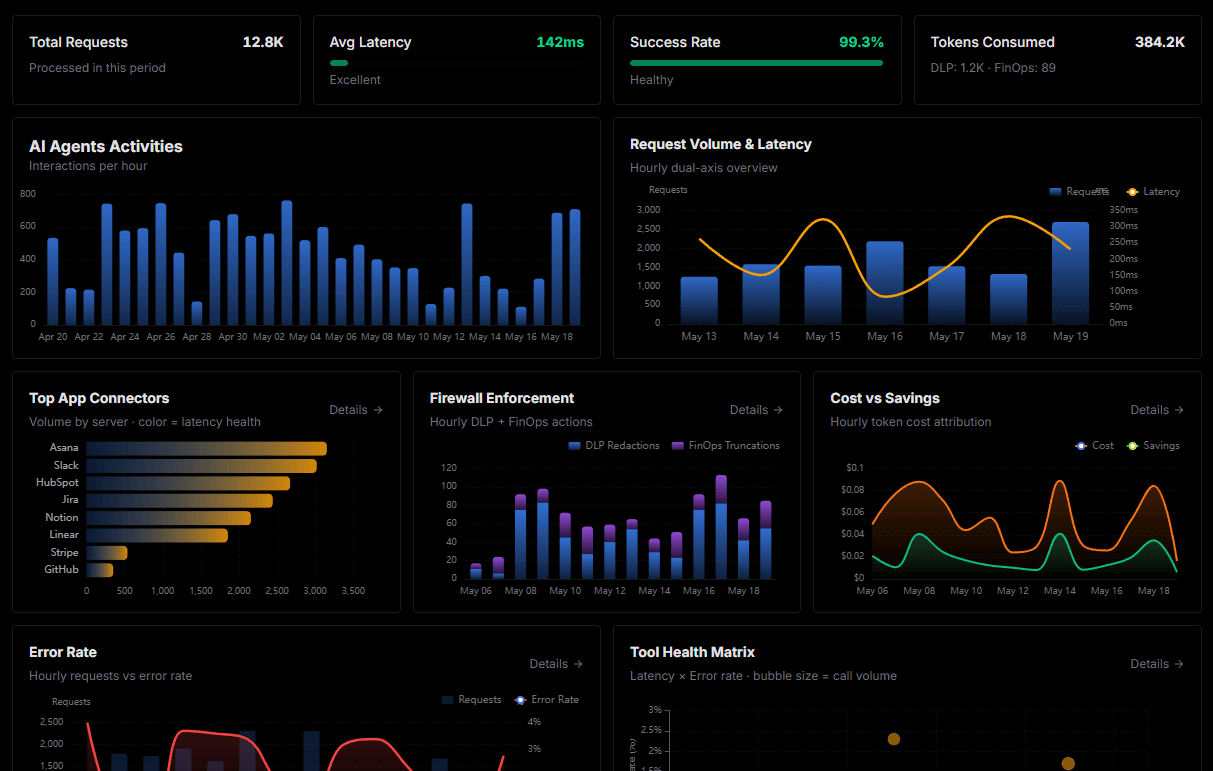
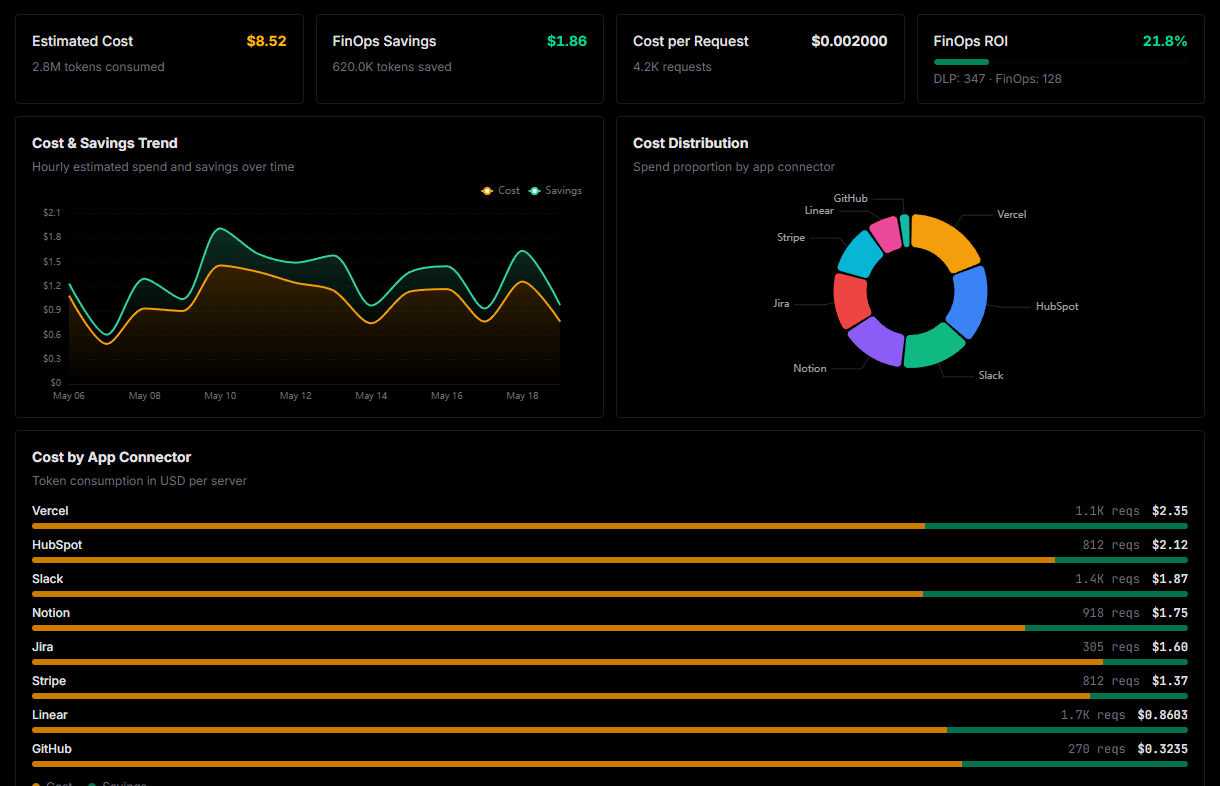
Explore our live AI Agents Analytics dashboard to see it all working
This dashboard is included when you connect NVIDIA API Catalog using Vinkius. You will never be left in the dark about what your AI agents are doing with your tools.
NVIDIA API Catalog and 4,000+ other AI tools. No hosting, no code, ready to use.
Professionals who connect NVIDIA API Catalog to Mastra AI through Vinkius don't need to write code, manage servers, or worry about security. Everything is pre-configured, secure, and runs automatically in the background.
Raw MCP | Vinkius | |
|---|---|---|
| Ready-to-use MCPs | Find and configure each manually | 4,000+ MCPs ready to use |
| Connection Setup | Manual coding & server setup | 1-click instant connection |
| Server Hosting | You host it yourself (needs 24/7 uptime) | 100% hosted & managed by Vinkius |
| Security & Privacy | Stored in plaintext config files | Bank-grade encrypted vault |
| Activity Visibility | Blind execution (no logs or tracking) | Live dashboard with real-time logs |
| Cost Control | Runaway AI token spend risk | Automatic budget limits |
| Revoking Access | Must delete files or code to stop | 1-click disconnect button |
How Vinkius secures
NVIDIA API Catalog for Mastra AI
Every request between Mastra AI and NVIDIA API Catalog is protected by our secure gateway. We automatically keep your sensitive data private, prevent unauthorized access, and let you disconnect instantly at any time.
Frequently asked questions
Can I explicitly route specific embedding vectors natively using the NVIDIA integration matrix?
Yes! Utilize generate_embeddings providing explicit logic extracting arrays natively isolating endpoints safely.
How do I explicitly explore active LLMs natively hosted inside the NVIDIA catalog bounds?
Target explicit matrices natively calling list_foundation_models returning catalog endpoints safely explicitly mapping bounds secure natively.
Does this require local Docker execution mapping explicitly NVIDIA parameters transparently?
No, this explicitly pings the hosted Cloud API. For local Docker metrics natively, switch to nvidia-nim-mcp enforcing natively local boundaries.
How does Mastra AI connect to MCP servers?
Create an MCPClient with the server URL and pass it to your agent. Mastra discovers all tools and makes them available with full TypeScript types.
Can Mastra agents use tools from multiple servers?
Yes. Pass multiple MCP clients to the agent constructor. Mastra merges all tool schemas and the agent can call any tool from any server.
Does Mastra support workflow orchestration?
Yes. Mastra has a built-in workflow engine that lets you chain MCP tool calls with branching logic, error handling, and parallel execution.
createMCPClient not exported
Install: npm install @mastra/mcp
Explore More MCP Servers
View all →
Landbot
8 toolsEmpower your AI to generate, route, and interact with conversational chatbots and customers naturally.

Harness
11 toolsAutomate CI/CD and DevOps workflows via Harness — manage pipelines, executions, and secrets directly from any AI agent.

Terraform Cloud (HCP)
42 toolsManage infrastructure lifecycle via Terraform Cloud (HCP) — list organizations, manage workspaces, trigger runs, and inspect state outputs directly from your AI agent.

ZoomInfo
8 toolsEquip your AI agent with direct access to ZoomInfo — search company and contact records, enrich lead data, and build prospect lists without opening the ZoomInfo platform.