Bring Llm Observability
to Pydantic AI
Create your Vinkius account to connect Helicone (LLM Observability) to Pydantic AI and start using all 10 AI tools in minutes. Fully managed, enterprise secure, and ready to use without writing a single line of code. No hosting, no server setup — just connect and start using.
Compatible with every major AI agent and IDE
 Gemini
Gemini
What is the Helicone (LLM Observability) MCP Server?
Connect your Helicone account to any AI agent and take full control of your LLM observability and gateway monitoring through natural conversation.
What you can do
- Request Monitoring — Query deep proxy logs to inspect exact prompts and outputs sent to LLM APIs directly from your agent
- Cost Analysis — Break down spending by model, user, or custom metadata properties to monitor your AI burn rate in real-time
- Latency Optimization — Measure Time To First Token (TTFT) and pinpoint slowness caused by specific upstream LLM providers
- Prompt Management — Access managed prompt versions and track iterative changes in your AI instruction logic natively
- Session Tracing — Isolate and analyze multi-turn graph traces connecting consecutive LLM calls to debug complex agentic workflows
- User Insights — Track precise LLM interactions based on Helicone tags and identify your most active human clients
- Feedback & RLHF — Extract user critiques (Thumbs Up/Down) and log offline Human-in-the-Loop verdicts to improve model grounding
How it works
- Subscribe to this server
- Enter your Helicone API Key
- Start monitoring your LLM infrastructure from Claude, Cursor, or any MCP-compatible client
Who is this for?
- LLM Engineers — debug prompt performance and measure TTFT latency across multiple upstream providers
- Product Owners — monitor AI spending and calculate costs per user, feature, or organization
- Data Scientists — analyze user feedback and improve model response quality through logged critiques
- DevOps/SREs — ensure the availability and reliability of your AI gateway and proxy layers
Built-in capabilities (10)
Irreversibly vaporize explicit validations extracting rich Churn flags
Identify precise active arrays spanning native Gateway auth
Identify precise active arrays spanning native Hold parsing
Perform structural extraction of properties driving active Account logic
Inspect deep internal arrays mitigating specific Plan Math
Provision a highly-available JSON Payload generating hard Customer bindings
Retrieve explicit Cloud logging tracing explicit Vault limits
Identify bounded CRM records inside the Headless Helicone Platform
Enumerate explicitly attached structured rules exporting active Billing
Dispatch an automated validation check routing explicit Gateway history
Why Pydantic AI?
Pydantic AI validates every Helicone (LLM Observability) tool response against typed schemas, catching data inconsistencies at build time. Connect 10 tools through Vinkius and switch between OpenAI, Anthropic, or Gemini without changing your integration code. full type safety, structured output guarantees, and dependency injection for testable agents.
- —
Full type safety: every MCP tool response is validated against Pydantic models, catching data inconsistencies before they reach your application
- —
Model-agnostic architecture. switch between OpenAI, Anthropic, or Gemini without changing your Helicone (LLM Observability) integration code
- —
Structured output guarantee: Pydantic AI ensures tool results conform to defined schemas, eliminating runtime type errors
- —
Dependency injection system cleanly separates your Helicone (LLM Observability) connection logic from agent behavior for testable, maintainable code
Helicone (LLM Observability) in Pydantic AI
Why run Helicone (LLM Observability) with Vinkius?
The Helicone (LLM Observability) connection runs on our fully managed, secure cloud infrastructure. We handle the hosting, maintenance, and security so you don't have to deal with servers or code. All 10 tools are ready to work instantly without any complex setup.
You stay in complete control of your data. Your AI only accesses the information you approve, keeping your sensitive passwords and private details completely safe. Plus, with automatic optimizations, your AI works faster and more efficiently.
* Every connection is hosted and maintained by Vinkius. We handle the security, updates, and infrastructure so you don't have to write code or manage servers. See our infrastructure
Over 4,000 integrations ready for AI agents
Explore a vast library of pre-built integrations, optimized and ready to deploy.
Connect securely in under 30 seconds
Generate tokens to authenticate and link external services in a single step.
Complete visibility into every agent action
Audit live requests, latency, success rates, and active security compliance policies.
Optimize spending and track token ROI
Analyze real-time token consumption and cost metrics detailed by connection.
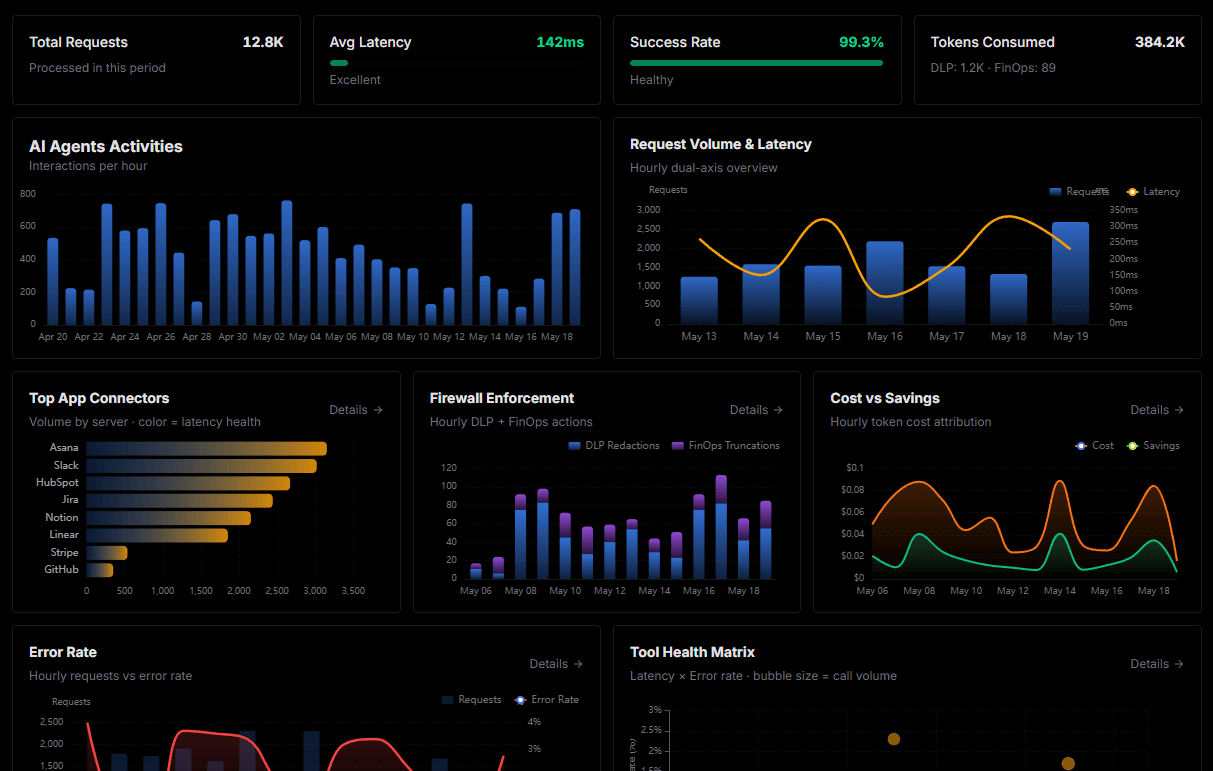
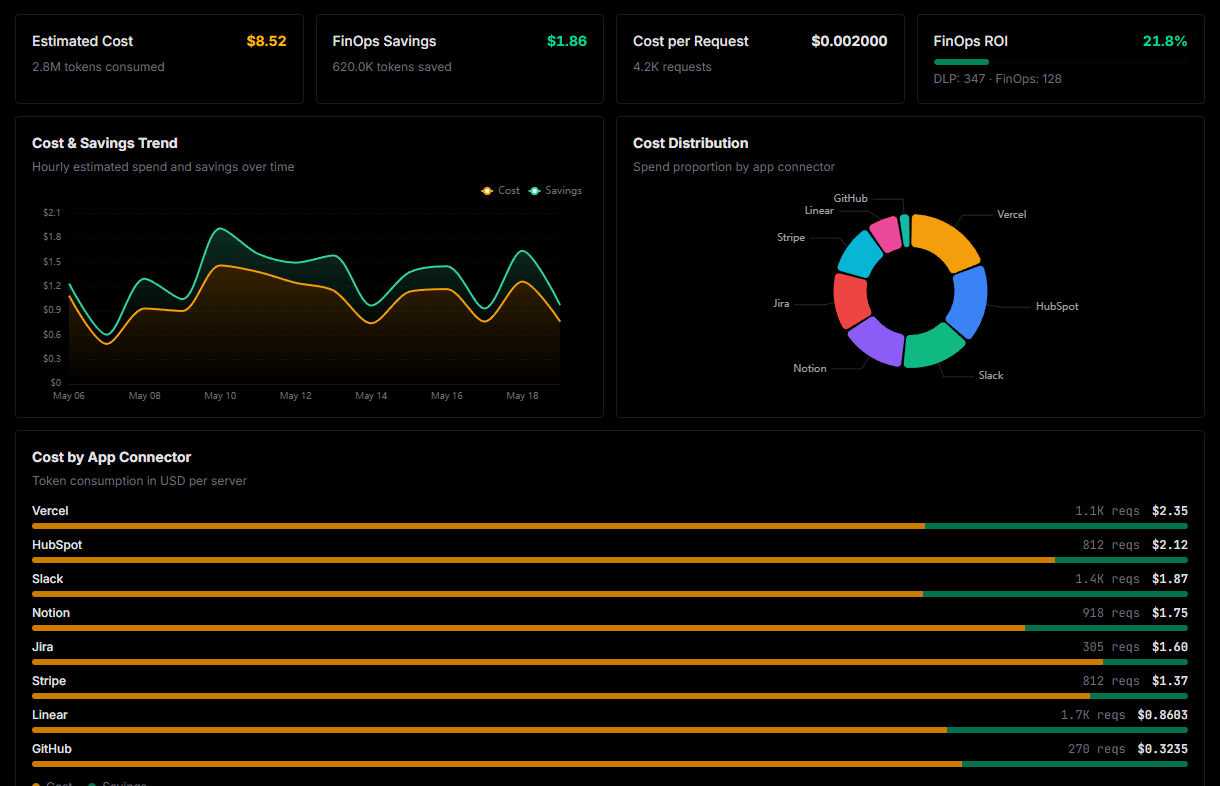
Explore our live AI Agents Analytics dashboard to see it all working
This dashboard is included when you connect Helicone (LLM Observability) using Vinkius. You will never be left in the dark about what your AI agents are doing with your tools.
Helicone (LLM Observability) and 4,000+ other AI tools. No hosting, no code, ready to use.
Professionals who connect Helicone (LLM Observability) to Pydantic AI through Vinkius don't need to write code, manage servers, or worry about security. Everything is pre-configured, secure, and runs automatically in the background.
Raw MCP | Vinkius | |
|---|---|---|
| Ready-to-use MCPs | Find and configure each manually | 4,000+ MCPs ready to use |
| Connection Setup | Manual coding & server setup | 1-click instant connection |
| Server Hosting | You host it yourself (needs 24/7 uptime) | 100% hosted & managed by Vinkius |
| Security & Privacy | Stored in plaintext config files | Bank-grade encrypted vault |
| Activity Visibility | Blind execution (no logs or tracking) | Live dashboard with real-time logs |
| Cost Control | Runaway AI token spend risk | Automatic budget limits |
| Revoking Access | Must delete files or code to stop | 1-click disconnect button |
How Vinkius secures
Helicone (LLM Observability) for Pydantic AI
Every request between Pydantic AI and Helicone (LLM Observability) is protected by our secure gateway. We automatically keep your sensitive data private, prevent unauthorized access, and let you disconnect instantly at any time.
Frequently asked questions
Can I see the exact prompt that caused a specific error?
Yes. Use the query_requests tool to fetch direct prompts and outputs from the proxy logs. You can filter by status or custom tags to find the exact interaction that needs debugging.
How do I track costs for a specific customer ID?
Ask your agent to query_costs and include your customer identity in the filter. Helicone maps costs per model and user, allowing you to see exactly how much each client is burning in LLM tokens.
Can my agent log human feedback into Helicone?
Absolutely. Use the log_feedback tool to inject offline Human-in-the-Loop verdicts or text critiques directly into Helicone's database, helping you refine your model's grounding over time.
How does Pydantic AI discover MCP tools?
Create an MCPServerHTTP instance with the server URL. Pydantic AI connects, discovers all tools, and generates typed Python interfaces automatically.
Does Pydantic AI validate MCP tool responses?
Yes. When you define result types as Pydantic models, every tool response is validated against the schema. Invalid data raises a clear error instead of silently corrupting your pipeline.
Can I switch LLM providers without changing MCP code?
Absolutely. Pydantic AI abstracts the model layer. your Helicone (LLM Observability) MCP integration works identically with OpenAI, Anthropic, Google, or any supported provider.
MCPServerHTTP not found
Update: pip install --upgrade pydantic-ai
Explore More MCP Servers
View all →
Recreation.gov (RIDB)
10 toolsAccess federal recreation data—find campgrounds, trails, and facilities across the US directly from your AI agent.

Matrix/Element
19 toolsAutomate your Matrix communications — manage rooms, send secure messages, and sync account state directly from your AI agent.

Discourse
10 toolsEquip your AI agent to manage forum topics, track community members, and monitor categories via the Discourse API.

AccuWeather
10 toolsEnterprise-grade weather intelligence — current conditions, forecasts, alarms, and activity indices via AI.