Bring Gpu Computing
to Mastra AI
Create your Vinkius account to connect RunPod to Mastra AI and start using all 7 AI tools in minutes. Fully managed, enterprise secure, and ready to use without writing a single line of code. No hosting, no server setup — just connect and start using.
Compatible with every major AI agent and IDE
 Gemini
Gemini
What is the RunPod MCP Server?
Connect your AI directly to RunPod, the leading cloud infrastructure provider for on-demand GPU computing and serverless execution. Empower your conversational agent to act as a highly proficient DevOp engineer, managing advanced computational workloads, exploring deployment options, and spinning up new hardware instances.
What you can do
- Manage Pods On-Demand — Effortlessly identify running and paused GPU machines across your cloud account (
list_pods,get_pod). Halt specific billable instances to control costs securely (stop_pod). - Provision GPU Workloads — Find verified templates or specific GPU architectures ready for deployment (
list_templates,list_gpu_types), and create entirely new hardware nodes immediately directly from chat (create_pod). - Audit Serverless Environments — Review all registered endpoints routing your containerized inference applications (
list_endpoints).
How it works
- Successfully enable the RunPod orchestration integration inside your core interface.
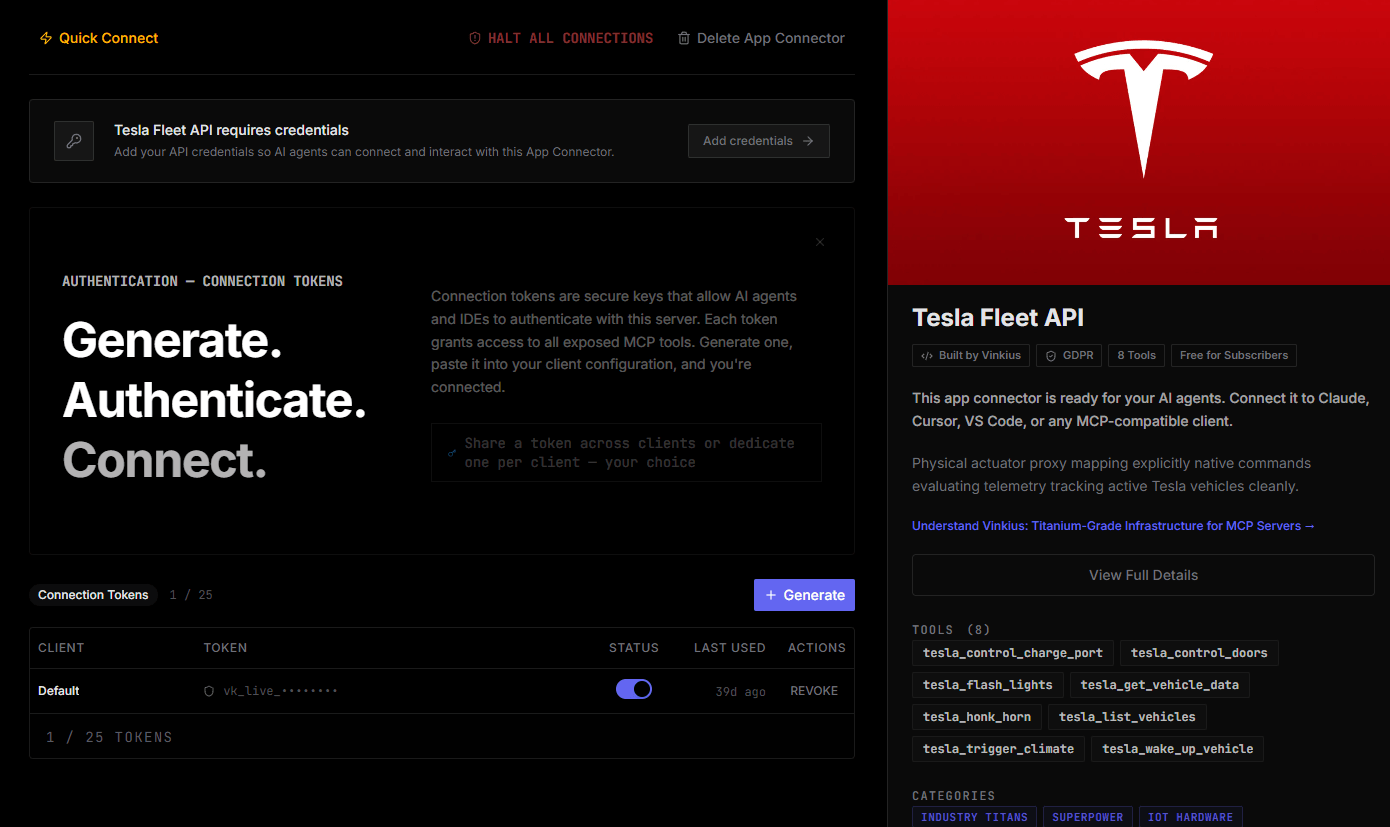
- Sign into your RunPod cloud console and navigate to 'Settings' > 'API Keys'.
- Generate a new API Key with Read/Write permissions and insert this secret inside the secure connection module below.
- Interact seamlessly: "List all active GPU pods and point out any that are sitting idle without active usage."
Who is this for?
- DevOps Engineers — Instantly provision and audit heavy workloads directly from chat interfaces without toggling through web dashboards.
- AI Developers — Manage high-power serverless LLM implementations organically via organic language requests.
Built-in capabilities (7)
Specify name, GPU type, and Docker image. Creates a new GPU pod
Retrieves details for a specific GPU pod
Lists all serverless endpoints
Lists available GPU hardware types
Lists all GPU pods in the account
Lists saved pod templates
Stops a running GPU pod
Why Mastra AI?
Mastra's agent abstraction provides a clean separation between LLM logic and RunPod tool infrastructure. Connect 7 tools through Vinkius and use Mastra's built-in workflow engine to chain tool calls with conditional logic, retries, and parallel execution. deployable to any Node.js host in one command.
- —
Mastra's agent abstraction provides a clean separation between LLM logic and tool infrastructure. add RunPod without touching business code
- —
Built-in workflow engine chains MCP tool calls with conditional logic, retries, and parallel execution for complex automation
- —
TypeScript-native: full type inference for every RunPod tool response with IDE autocomplete and compile-time checks
- —
One-command deployment to any Node.js host. Vercel, Railway, Fly.io, or your own infrastructure
RunPod in Mastra AI
Why run RunPod with Vinkius?
The RunPod connection runs on our fully managed, secure cloud infrastructure. We handle the hosting, maintenance, and security so you don't have to deal with servers or code. All 7 tools are ready to work instantly without any complex setup.
You stay in complete control of your data. Your AI only accesses the information you approve, keeping your sensitive passwords and private details completely safe. Plus, with automatic optimizations, your AI works faster and more efficiently.
* Every connection is hosted and maintained by Vinkius. We handle the security, updates, and infrastructure so you don't have to write code or manage servers. See our infrastructure
Over 4,000 integrations ready for AI agents
Explore a vast library of pre-built integrations, optimized and ready to deploy.
Connect securely in under 30 seconds
Generate tokens to authenticate and link external services in a single step.
Complete visibility into every agent action
Audit live requests, latency, success rates, and active security compliance policies.
Optimize spending and track token ROI
Analyze real-time token consumption and cost metrics detailed by connection.
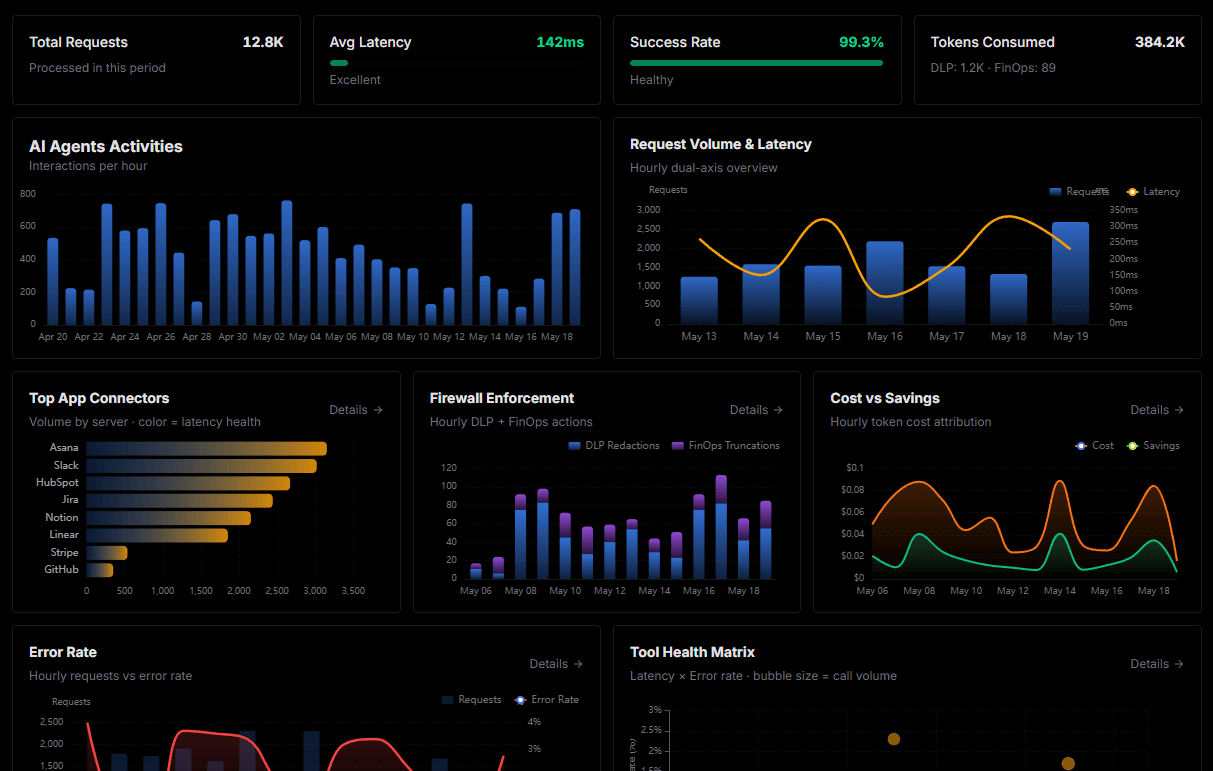
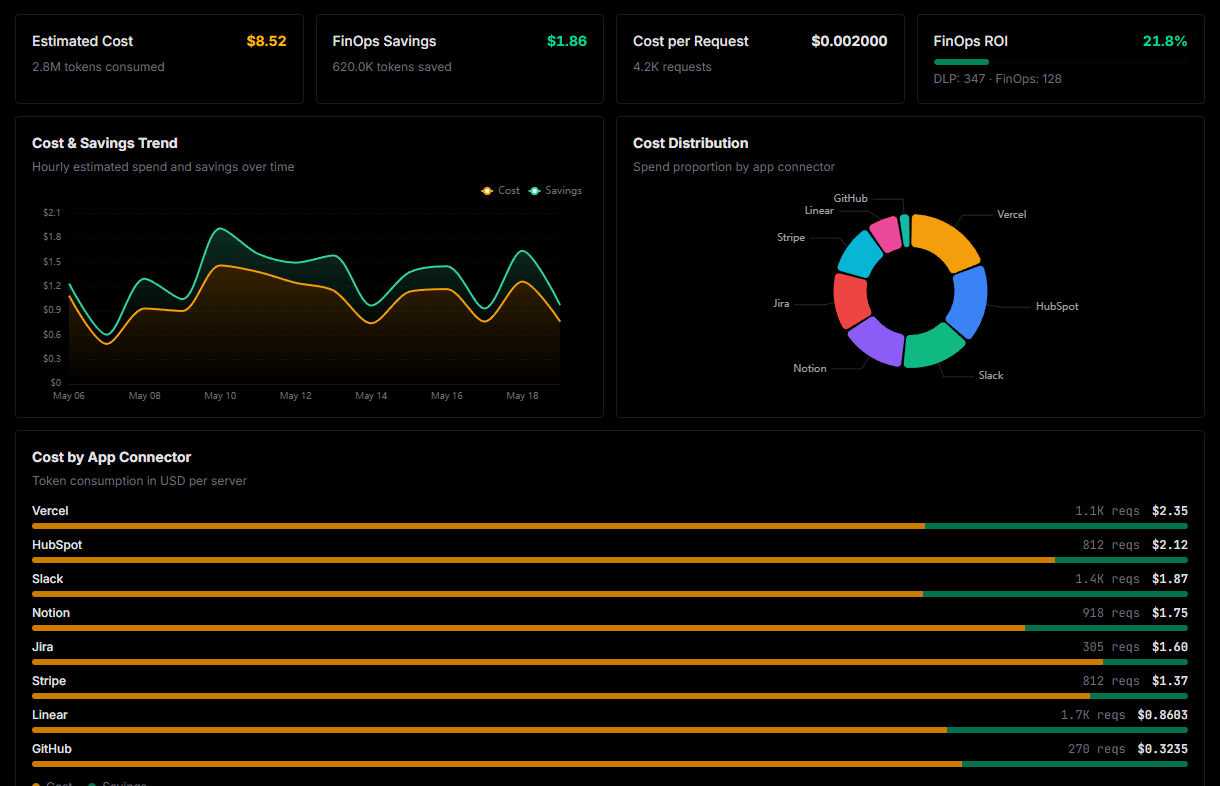
Explore our live AI Agents Analytics dashboard to see it all working
This dashboard is included when you connect RunPod using Vinkius. You will never be left in the dark about what your AI agents are doing with your tools.
RunPod and 4,000+ other AI tools. No hosting, no code, ready to use.
Professionals who connect RunPod to Mastra AI through Vinkius don't need to write code, manage servers, or worry about security. Everything is pre-configured, secure, and runs automatically in the background.
Raw MCP | Vinkius | |
|---|---|---|
| Ready-to-use MCPs | Find and configure each manually | 4,000+ MCPs ready to use |
| Connection Setup | Manual coding & server setup | 1-click instant connection |
| Server Hosting | You host it yourself (needs 24/7 uptime) | 100% hosted & managed by Vinkius |
| Security & Privacy | Stored in plaintext config files | Bank-grade encrypted vault |
| Activity Visibility | Blind execution (no logs or tracking) | Live dashboard with real-time logs |
| Cost Control | Runaway AI token spend risk | Automatic budget limits |
| Revoking Access | Must delete files or code to stop | 1-click disconnect button |
How Vinkius secures
RunPod for Mastra AI
Every request between Mastra AI and RunPod is protected by our secure gateway. We automatically keep your sensitive data private, prevent unauthorized access, and let you disconnect instantly at any time.
Frequently asked questions
Can the AI forcefully terminate or delete critical production endpoint fleets on demand?
No. This module safely allows the AI to only pause and manage running instances. Destructive deletion actions (like completely erasing a pod) are intentionally prohibited by the tooling design to protect your critical compute resources from unintended loss.
Can the AI provision large GPU arrays automatically?
Yes. Using the create_pod capability, the AI can query the available hardware models (such as A100 or H100) and immediately launch new Docker clusters based on existing community templates, simplifying complex DevOps scaling actions significantly.
Will the AI know the billing state or the real-time cost of running each endpoint?
No. The current RunPod AI module is concentrated on operational control and system orchestration, such as discovering inactive processes and booting new instances. Deep billing analytics or invoice extraction is not natively integrated in the commands exposed to the AI at this time.
How does Mastra AI connect to MCP servers?
Create an MCPClient with the server URL and pass it to your agent. Mastra discovers all tools and makes them available with full TypeScript types.
Can Mastra agents use tools from multiple servers?
Yes. Pass multiple MCP clients to the agent constructor. Mastra merges all tool schemas and the agent can call any tool from any server.
Does Mastra support workflow orchestration?
Yes. Mastra has a built-in workflow engine that lets you chain MCP tool calls with branching logic, error handling, and parallel execution.
createMCPClient not exported
Install: npm install @mastra/mcp
Explore More MCP Servers
View all →
SimplyBook.me
10 toolsEnable your AI agent to manage appointments, browse staff calendars, and handle client records via the SimplyBook.me scheduling platform.

Aliyun CAPTCHA / 阿里云验证码
2 toolsAlibaba Cloud's dominant anti-bot service — verify tickets and audit security risk via AI.

Transloadit
10 toolsManage your media processing pipelines, encode videos, resize images, and oversee your file cloud instantly via an AI agent.

Givebutter
12 toolsManage fundraising campaigns, track donations, and oversee donors via AI agents with Givebutter.