Bring Web Automation
to LlamaIndex
Create your Vinkius account to connect Apify to LlamaIndex and start using all 10 AI tools in minutes. Fully managed, enterprise secure, and ready to use without writing a single line of code. No hosting, no server setup — just connect and start using.
Compatible with every major AI agent and IDE
 Gemini
Gemini
What is the Apify MCP Server?
Connect your Apify workspace to your AI agent and seamlessly direct full-stack web scraping and data extraction workflows through natural conversation.
What you can do
- Discover & Run Actors — Browse all scraper bots (Actors) available in your account. Fire them off asynchronously or synchronously for fast, targeted scraping
- Extract Datasets — Pull robust structured data formats out of completed runs. Retrieve detailed JSON records directly into the agent's context window
- Fetch Key-Value Stores — Programmatically read snapshots, cached HTML pages, or screenshots from the Apify Key-Value repositories mapped to a run
- Job Control & Scalability — Stop hanging scraper jobs, queue new dynamic URLs mid-run, or inspect deep usage analytics, compute units, and webhooks limits
How it works
- Subscribe to this server
- Enter your Personal Apify API Token
- Start exploring and interacting with data extraction routines securely via Claude or Cursor
Who is this for?
- Data Engineers — trigger scheduled extraction logic seamlessly and map Apify objects within a conversational QA check
- Market Researchers — command the AI to scrape product prices using Apify actors and compile the JSON datasets into readable markdown tables
- AI Developers — augment your agent's real-time capabilities by feeding it massive structured site data freshly scraped via headless browsers
Built-in capabilities (10)
Any data already scraped and pushed to the dataset is preserved. The run status changes to ABORTED. Use this to stop runaway scrapes or when sufficient data has been collected. Graceful shutdown depends on the actor implementation. Abort an active Apify actor run
Essential for monitoring consumption and avoiding overage charges. Check Apify account subscription limits and compute unit usage
The datasetId is found in the run object (defaultDatasetId). Supports pagination via limit (max items per page) and offset (starting position). Returns an array of JSON objects containing the scraped data fields. Use limit=1000 for bulk downloads. Export structured JSON data from an Apify dataset
Key-value stores hold arbitrary data like screenshots (OUTPUT), configuration files, or intermediate results. The storeId comes from the run object (defaultKeyValueStoreId). Common keys include "OUTPUT", "INPUT", and "SCREENSHOT". Retrieve an item from an Apify actor key-value store
Poll this endpoint to track long-running scrapes. Check the status and metadata of a specific Apify actor run
Includes owned actors and those from the Apify Store that have been saved. Each entry contains the actorId, name, description, and default run configuration. Use the actorId to trigger runs. List all accessible actors in the Apify account
RUN.SUCCEEDED, ACTOR.RUN.FAILED), target URLs, and associated actor IDs. Webhooks enable event-driven architectures by notifying external systems when actor runs complete or fail. List all configured webhooks in the Apify account
Pass the queueId (from the run object) and a JSON string array of request objects, e.g., [{"url":"https://...","uniqueKey":"..."}]. This enables dynamic crawling where new pages are discovered and added during execution. Dynamically push new URLs to an active Apify request queue
Pass the actorId (e.g., "apify/web-scraper" or a custom ID) and a JSON string with the input configuration (start URLs, proxy settings, max pages, etc.). Returns immediately with a runId. Use ap.get_run to poll for completion and ap.get_dataset_items to retrieve extracted data. Start an Apify actor asynchronously with custom JSON input
run_actor but waits for the actor to finish before returning. The response includes the full run object with defaultDatasetId for immediate data retrieval. Best for short-lived actors (under 5 minutes). For long-running scrapes, use the async ap.run_actor instead. Run an Apify actor and block until completion (synchronous)
Why LlamaIndex?
LlamaIndex agents combine Apify tool responses with indexed documents for comprehensive, grounded answers. Connect 10 tools through Vinkius and query live data alongside vector stores and SQL databases in a single turn. ideal for hybrid search, data enrichment, and analytical workflows.
- —
Data-first architecture: LlamaIndex agents combine Apify tool responses with indexed documents for comprehensive, grounded answers
- —
Query pipeline framework lets you chain Apify tool calls with transformations, filters, and re-rankers in a typed pipeline
- —
Multi-source reasoning: agents can query Apify, a vector store, and a SQL database in a single turn and synthesize results
- —
Observability integrations show exactly what Apify tools were called, what data was returned, and how it influenced the final answer
Apify in LlamaIndex
Why run Apify with Vinkius?
The Apify connection runs on our fully managed, secure cloud infrastructure. We handle the hosting, maintenance, and security so you don't have to deal with servers or code. All 10 tools are ready to work instantly without any complex setup.
You stay in complete control of your data. Your AI only accesses the information you approve, keeping your sensitive passwords and private details completely safe. Plus, with automatic optimizations, your AI works faster and more efficiently.
* Every connection is hosted and maintained by Vinkius. We handle the security, updates, and infrastructure so you don't have to write code or manage servers. See our infrastructure
Over 4,000 integrations ready for AI agents
Explore a vast library of pre-built integrations, optimized and ready to deploy.
Connect securely in under 30 seconds
Generate tokens to authenticate and link external services in a single step.
Complete visibility into every agent action
Audit live requests, latency, success rates, and active security compliance policies.
Optimize spending and track token ROI
Analyze real-time token consumption and cost metrics detailed by connection.
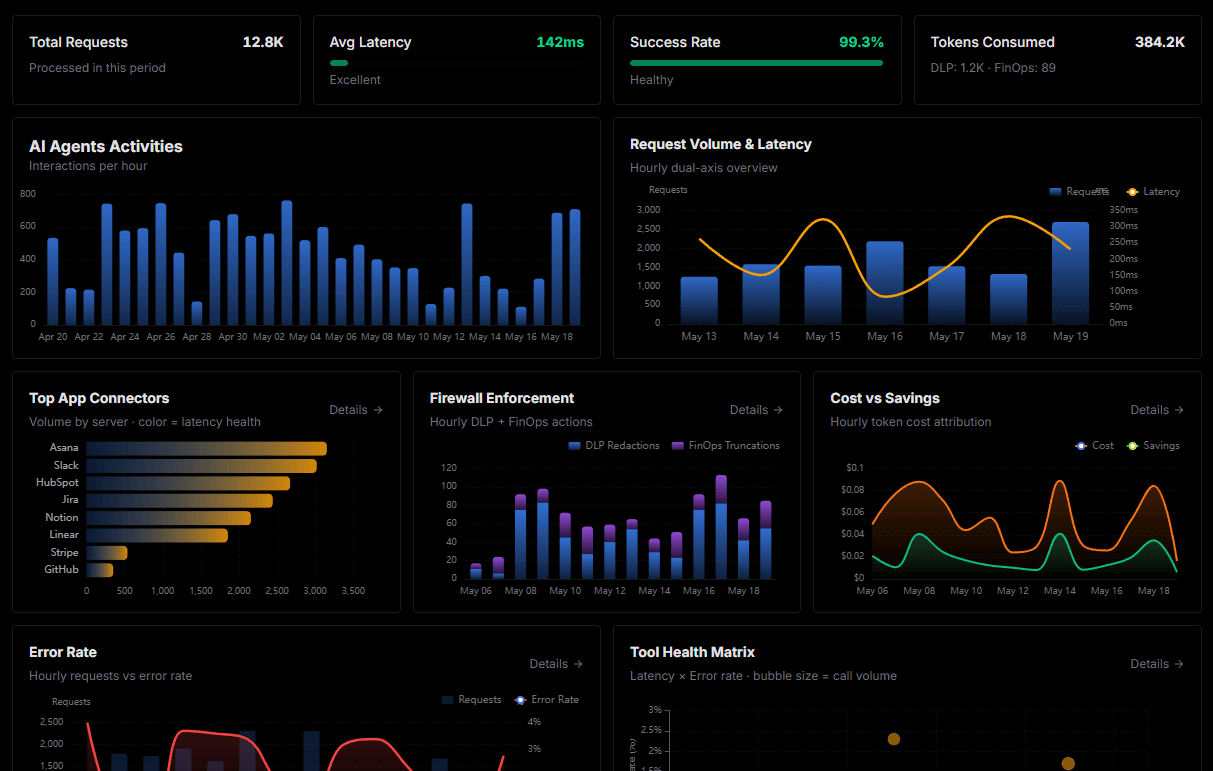
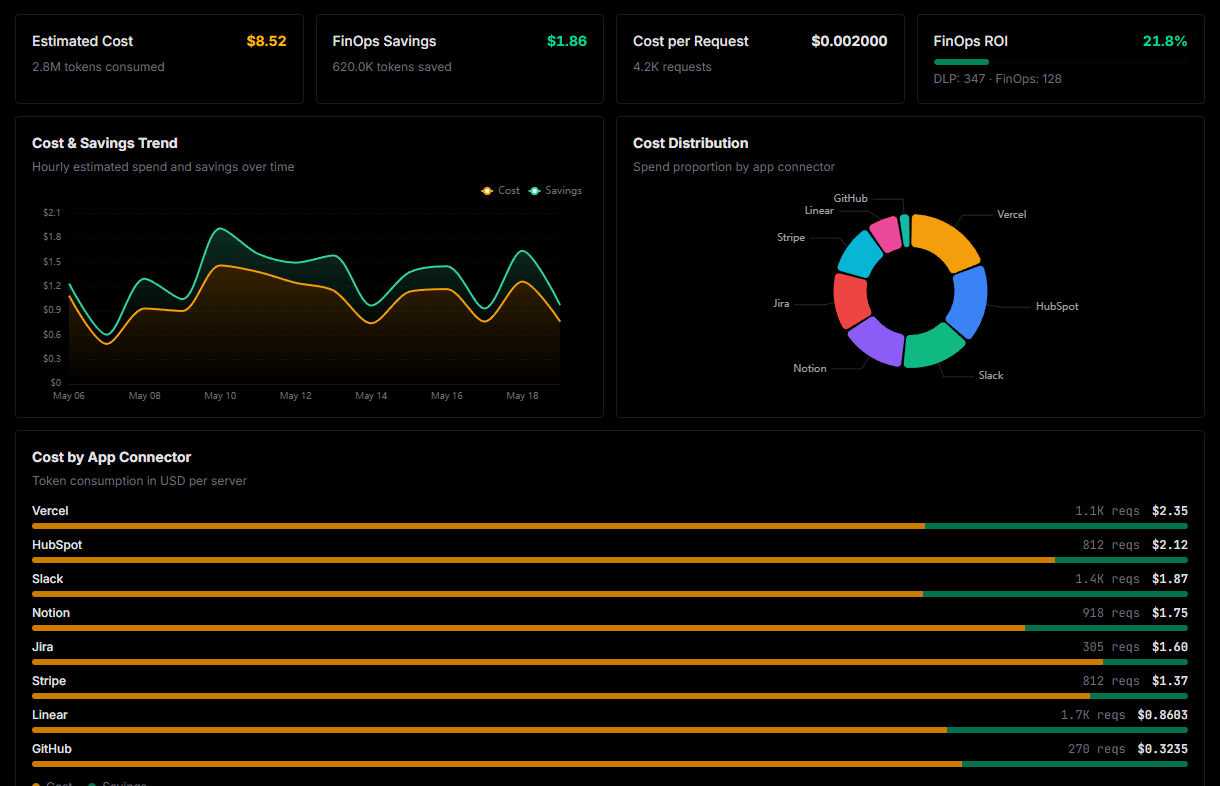
Explore our live AI Agents Analytics dashboard to see it all working
This dashboard is included when you connect Apify using Vinkius. You will never be left in the dark about what your AI agents are doing with your tools.
Apify and 4,000+ other AI tools. No hosting, no code, ready to use.
Professionals who connect Apify to LlamaIndex through Vinkius don't need to write code, manage servers, or worry about security. Everything is pre-configured, secure, and runs automatically in the background.
Raw MCP | Vinkius | |
|---|---|---|
| Ready-to-use MCPs | Find and configure each manually | 4,000+ MCPs ready to use |
| Connection Setup | Manual coding & server setup | 1-click instant connection |
| Server Hosting | You host it yourself (needs 24/7 uptime) | 100% hosted & managed by Vinkius |
| Security & Privacy | Stored in plaintext config files | Bank-grade encrypted vault |
| Activity Visibility | Blind execution (no logs or tracking) | Live dashboard with real-time logs |
| Cost Control | Runaway AI token spend risk | Automatic budget limits |
| Revoking Access | Must delete files or code to stop | 1-click disconnect button |
How Vinkius secures
Apify for LlamaIndex
Every request between LlamaIndex and Apify is protected by our secure gateway. We automatically keep your sensitive data private, prevent unauthorized access, and let you disconnect instantly at any time.
Frequently asked questions
How can the AI agent run a scrape on a list of product URLs?
First, find your specific scraping Actor ID via list_actors. Then, prompt your agent to execute run_actor, providing the target URLs formatted as a structured JSON input payload. It returns a 'Run ID'. You can poll this run via get_run, and once it succeeds, the agent calls get_dataset_items to pull all acquired data straight to your window.
Can the agent interact with run configurations mid-way during crawling?
Yes. If an Apify crawler is currently executing and utilizes a Request Queue, you can instruct your agent to call push_to_queue. Doing so dynamically ships new URLs to the active queue instance, extending the current web crawl without needing to stop or restart the Actor.
Can my AI automatically detect scraping timeouts and debug the failure?
Absolutely. Because your agent can track real execution flows with get_run, it's aware if it transitions to TIMED-OUT or FAILED states. Subsequently, you can ask the agent to examine the KV Store log outputs ensuring the underlying issue (e.g. captcha block, blocking proxy) is identified immediately.
How does LlamaIndex connect to MCP servers?
Use the MCP client adapter to create a connection. LlamaIndex discovers all tools and wraps them as query engine tools compatible with any LlamaIndex agent.
Can I combine MCP tools with vector stores?
Yes. LlamaIndex agents can query Apify tools and vector store indexes in the same turn, combining real-time and embedded data for grounded responses.
Does LlamaIndex support async MCP calls?
Yes. LlamaIndex's async agent framework supports concurrent MCP tool calls for high-throughput data processing pipelines.
BasicMCPClient not found
Install: pip install llama-index-tools-mcp
Explore More MCP Servers
View all →
BreezoMeter Air Quality & Pollen
2 toolsUniversal air quality intelligence — get real-time AQI, pollutants, and pollen data via AI.
Credly
10 toolsEquip your AI agent to manage digital badges, monitor issuance, and track recipient skills via the Credly API.
Toggl Plan
10 toolsManage your team's visual timelines, track project phases, and balance workloads securely via your AI agent.
NCDC Climate Data Online
10 toolsAccess authoritative historical weather and climate data via NCDC — track datasets, stations, and climate records directly from your AI agent.